효과적인 흐름 제어를 위한 고도의 Modular RAG 기법 - 테디노트
- 장소: 09.20(금) 서울 코엑스
- 주제: 효과적인 흐름 제어를 위한 고도의 Modular RAG 기법
- 연사: 테디노트
- 발표자료: https://bit.ly/3XTNAN5
TOC
- RAG 패러다임의 변화: Naive RAG -> Advanced RAG -> Modular RAG
- Modular RAG 소개
- LangGraph
- Modular RAG Patterns
- Modular RAG 적용사례
Why RAG?
RAG가 등장하게 된 배경
LLM은 다음과 같은 문제를 가지고 있다.
- 할루시네이션
- 할루시네이션은 모델이 잘못된 정보를 자신감 있게 제시
- 최신 정보의 반영 안됨
- 대규모 언어 모델의 학습과정이 복잡하고 시간과 리소스가 많이 소요됨
- 모델의 지식은 학습 데이터의 컷오프 날짜에 제한되어 있고, 실시간 업데이트가 어렵기 때문에 최신 정보 반영이 지연된다.
- 도메인 특화
- 일반적인 LLM은 광범위한 지식을 다루지만, 특정 기업이나 조직의 고유한 정보는 포함하지 않음
- 기업 특화 정보를 활용하기 위해서는 추가적인 파인튜닝이나 맞춤형 학습이 필요
- 지식의 불분명한 출처
- LLM은 학습 데이터에서 얻은 정보를 종합하여 답변을 생성하므로, 특정 정보의 정확한 출처를 제시하기 어려움
RAG란?
Retrieval(검색) - Augmented(증강) - Generation(생성)
- 기존의 LLM이 답변을 생성하는 과정에 “검색”을 추가하여 답변에 참고할만한 정보를 제공하는 것이다.
RAG 효과
| 구축 및 유지보수 비용 | 구축의 복잡성 |
|---|---|
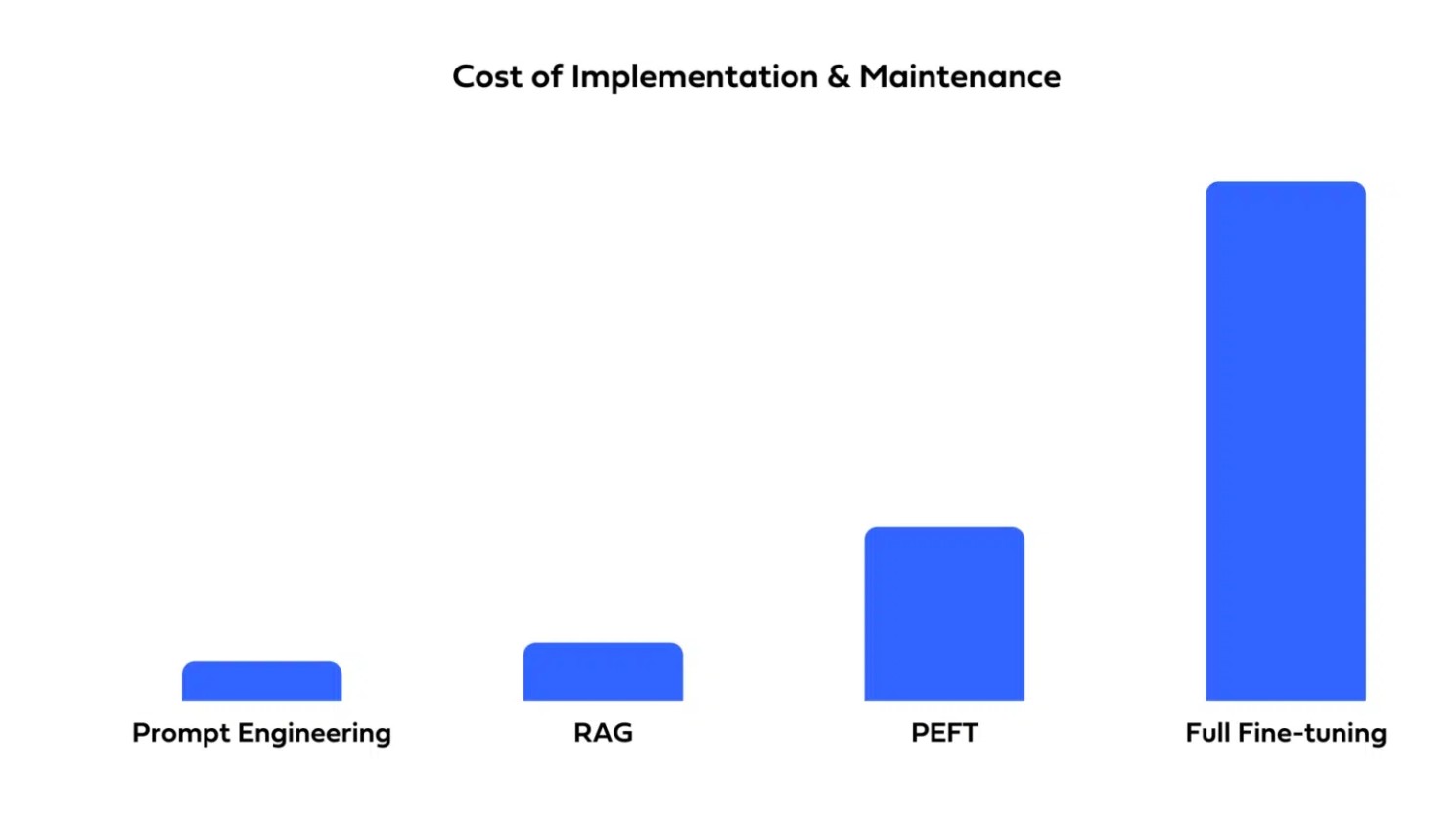 |
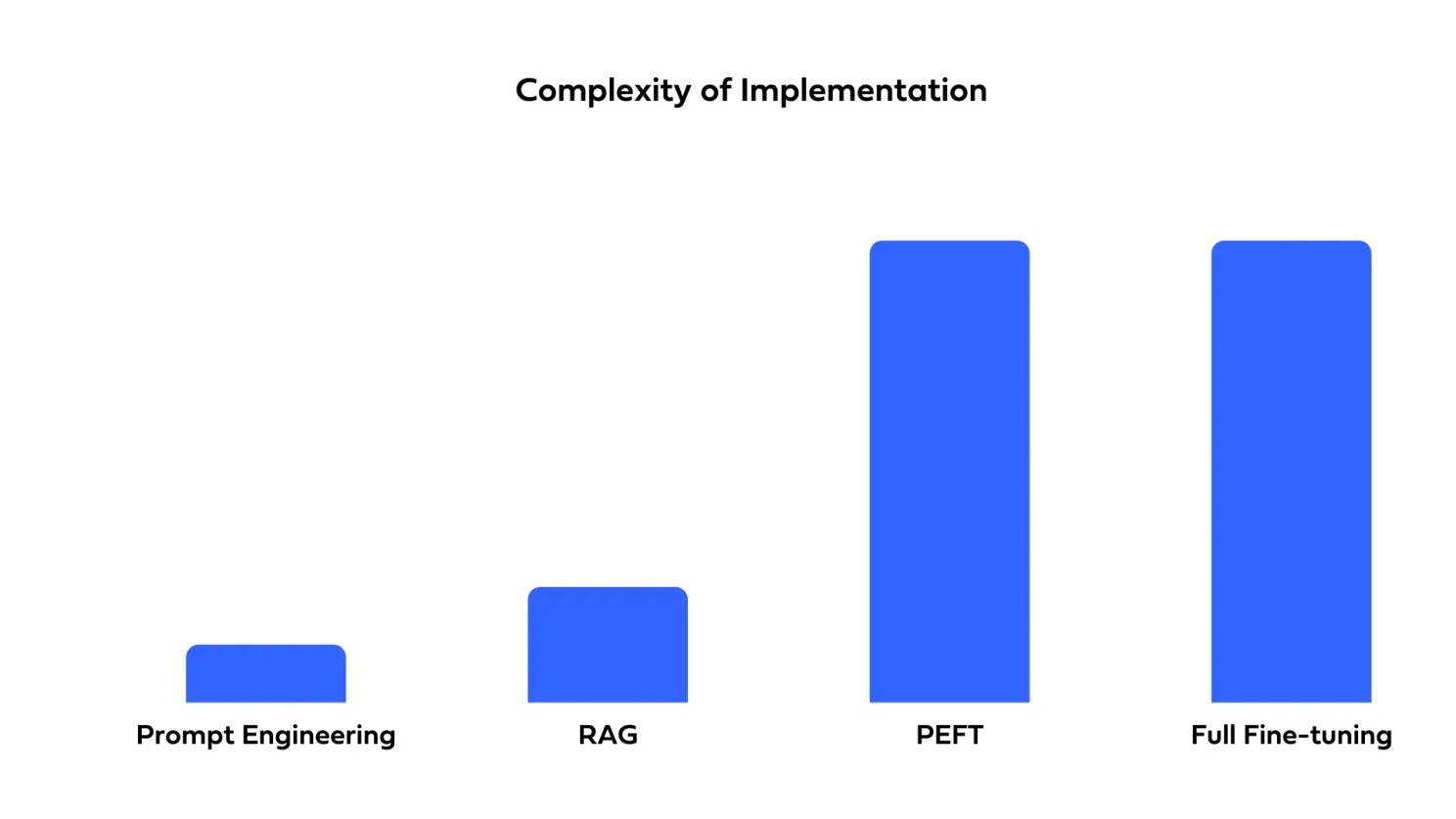 |
| 도메인별 용어 특화 | 최신 정보로 답변 |
|---|---|
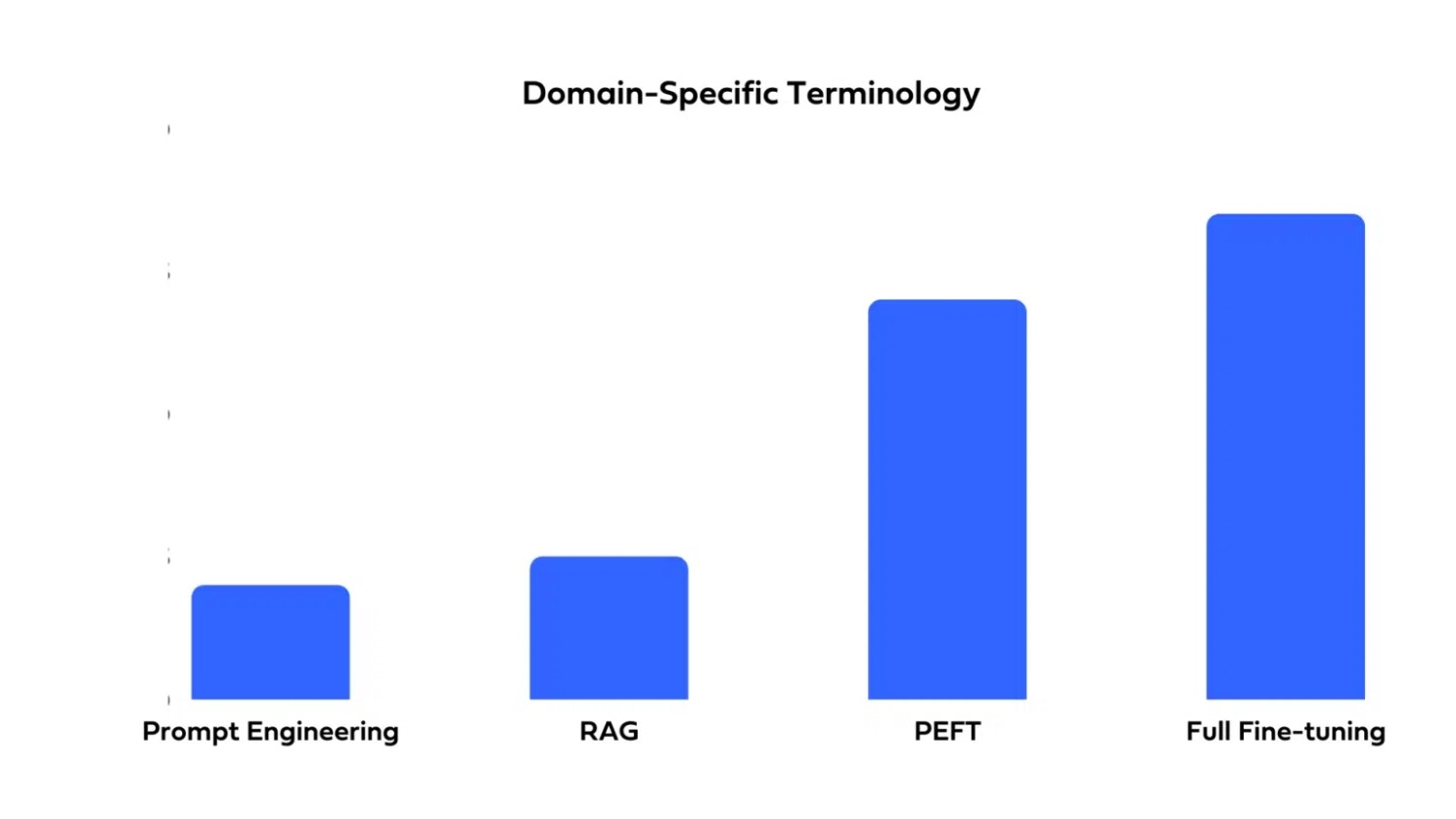 |
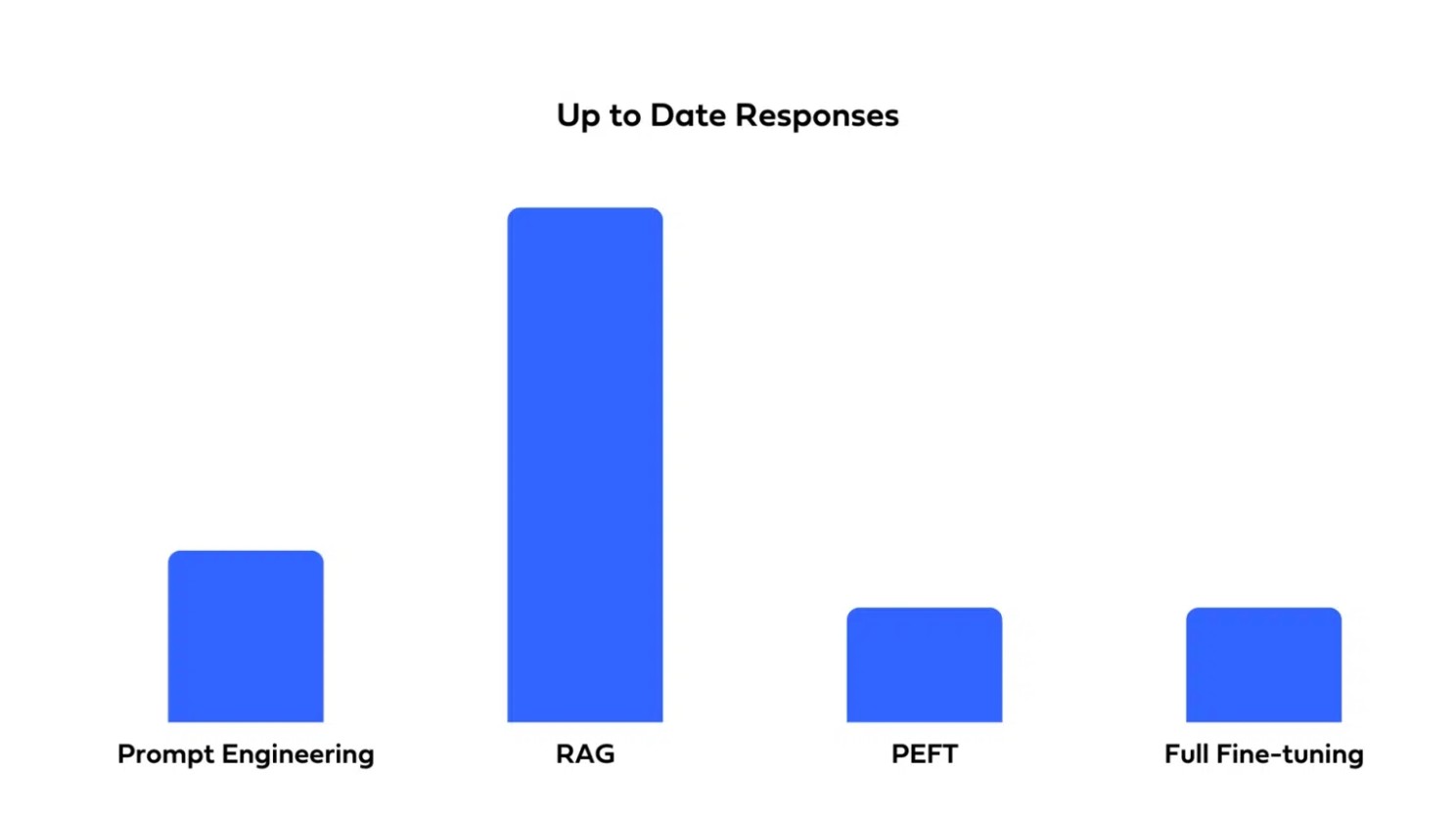 |
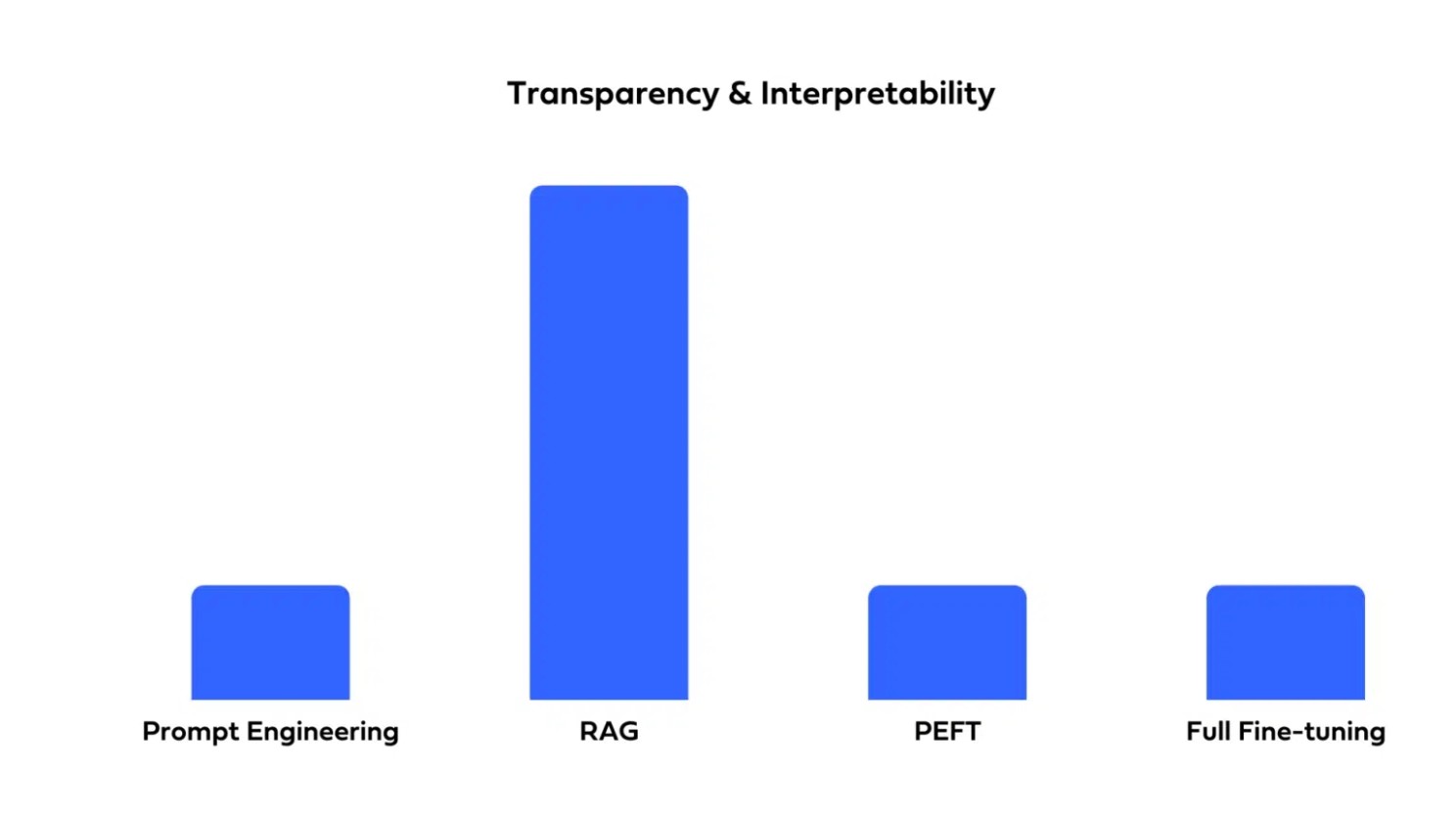
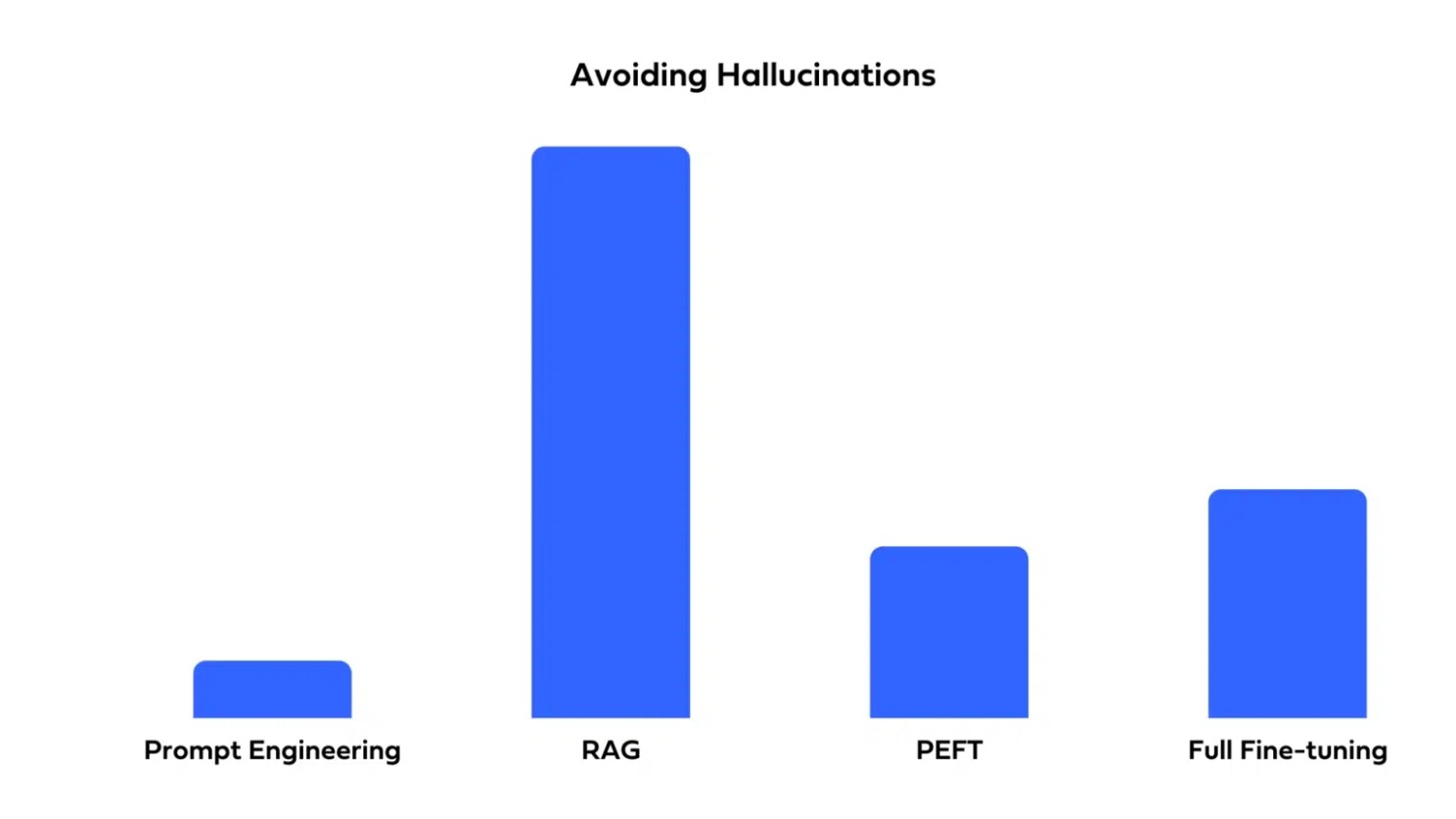
| 답변 과정의 투명성 및 해석 가능성 | 할루시네이션 감소 |
|---|---|
 |
 |
대표적인 RAG 방법론
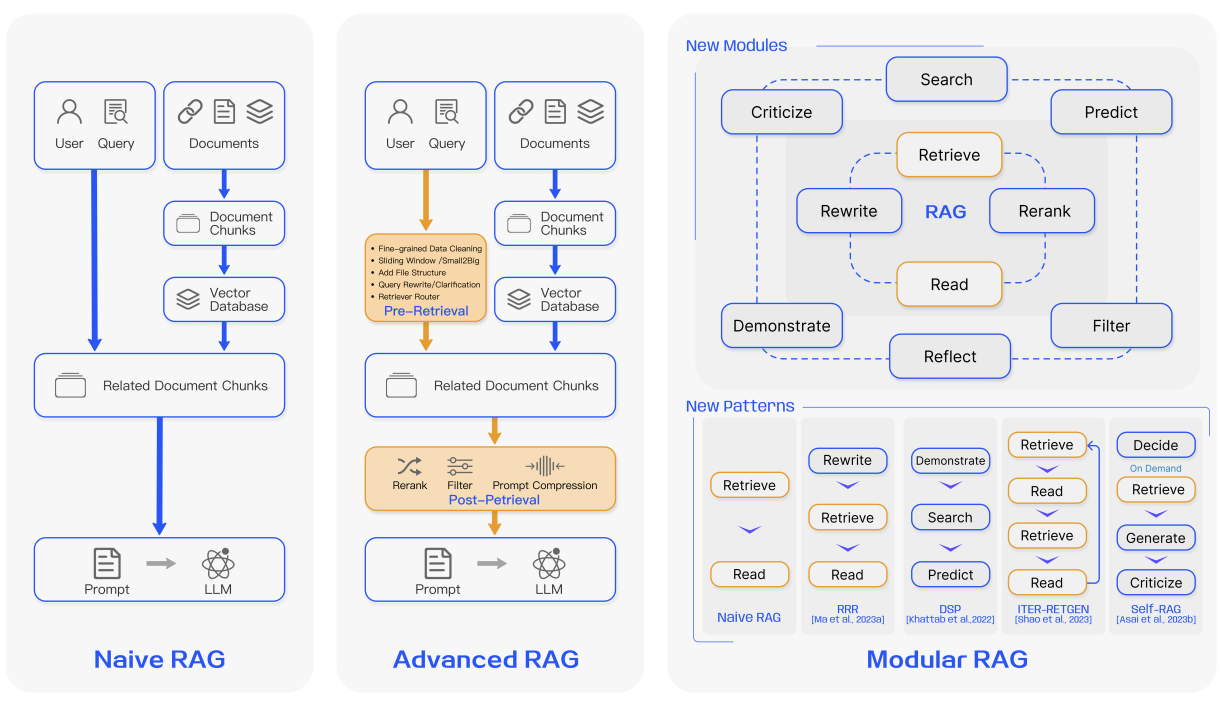
RAG의 패러다임 변화
이전 방법론의 한계를 뛰어넘을 수 있는 여러가지 시도
- Naive RAG -> Advanced RAG -> Modular RAG
- 패러다임은 End-to-End RAG 파이프라인의 변화에 따라 나뉨
- Naive RAG -> AdvanceRAG
- 더 나은 RAG 성능개선에 초점을 맞춤
- Advanced RAG -> Modular RAG
- RAG를 프로덕션 레벨에서의 유지보수, 효율적인 설계를 고려
Naive RAG
출처: https://python.langchain.com/v0.1/docs/use_cases/question_answering/
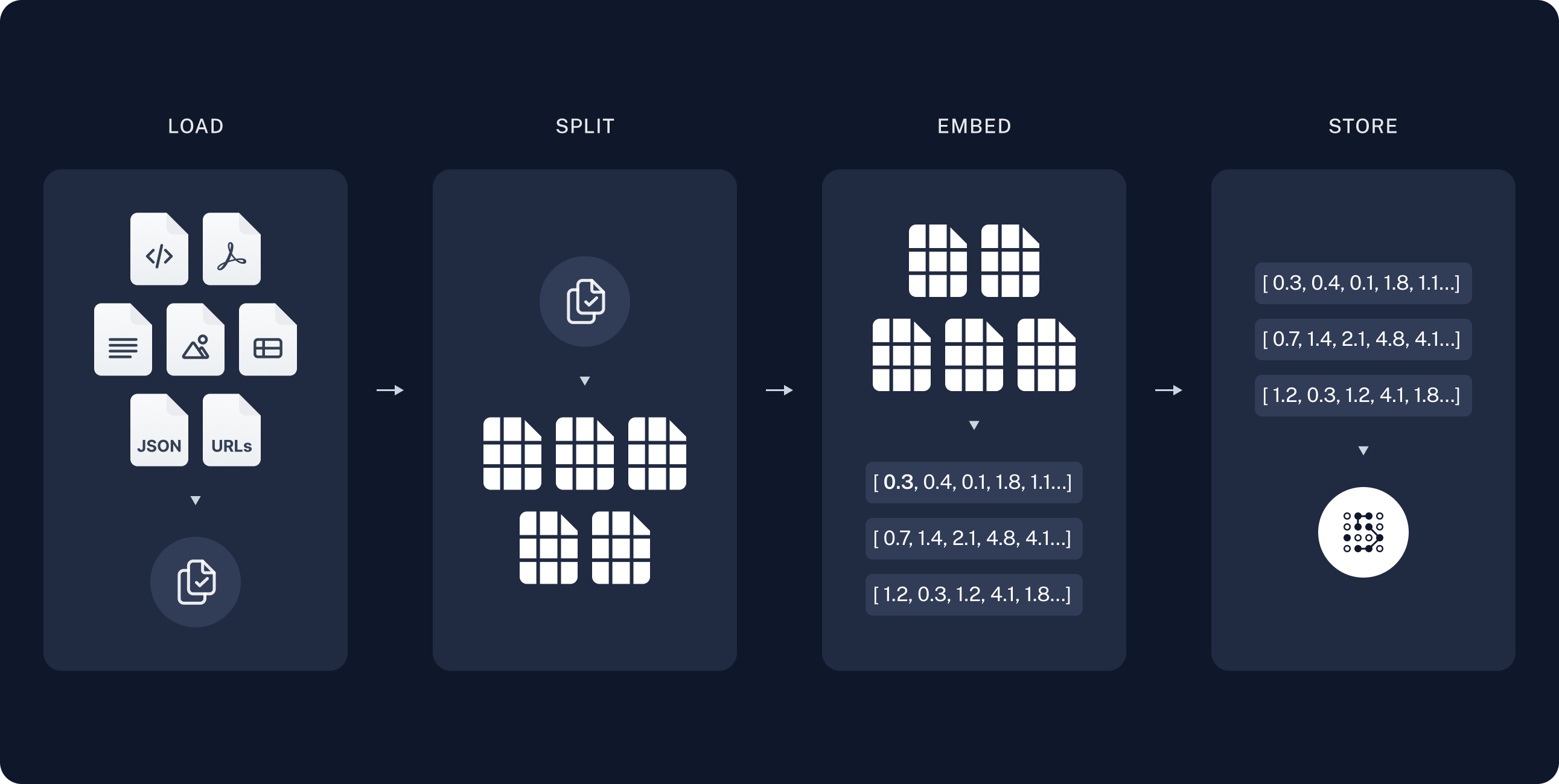
검색(Retrieve) - 읽기(Read) 프레임워크
사전 단계
- Indexing: PDF, Word, Markdown 등에서 텍스트 데이터 추출
- Chunking: 작은 단위로 분할
- Embedding: Vector로 인코딩
- Database: 임베딩된 Vector를 DB에 저장
실행 단계
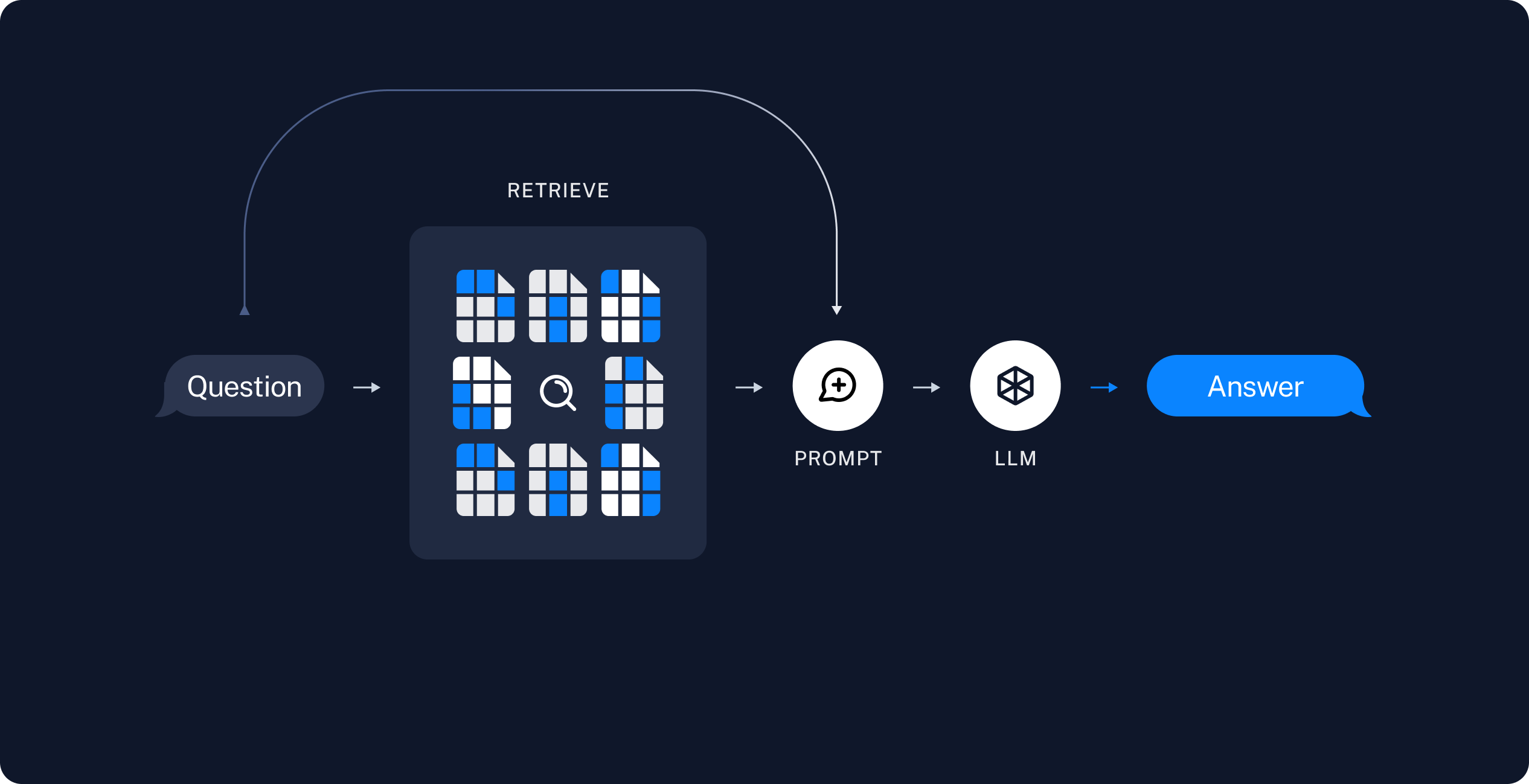
- Retrieve: Database 에서 질문(Query)에 답변하기 위한 정보 검색
- Generation: 검색된 정보를 문맥(Context)에 추가하여 답변 생성
Navie RAG의 한계
- 쿼리에 대한 얕은 이해
- 쿼리와 문서 Chunk 사이의 의미론적 유사성이 항상 일치하는 것은 아님
- 검색을 위해 유사도 계산에만 의존하는 것은 쿼리와 문서간의 관계에 대한 심층적인 탐색이 부족
- 검색 중복 및 노이즈
- 검색된 모든 Chunk를 LLM에 직접 공급하는 것이 항상 유익한 것은 아님
- 연구에 따르면 중복되고 노이즈가 많은 정보는 LLM가 핵심정보를 식별하는데 방해가 되어 잘못된 응답을 생성(Hallucination) 할 위험이 높아질 수 있음
Advanced RAG

이전의 Naive RAG 가 가지고 있었던 한계를 극복하기 위한 다양한 고급 방법론
- Indexing
- 계층적 구조의 Indexing
- Semantic Chunking
- Pre-Retrieval
- Query Rewrite, Query Expansion
- Query Transformation
- Retrieval
- Hybrid Search(키워드 검색 + 시맨틱 검색)
- Post-Retrieval
- Reranker, Reorder
Indexing
- Metadata
- metadata에 연도,출처(파일명,URL)등 을 추가
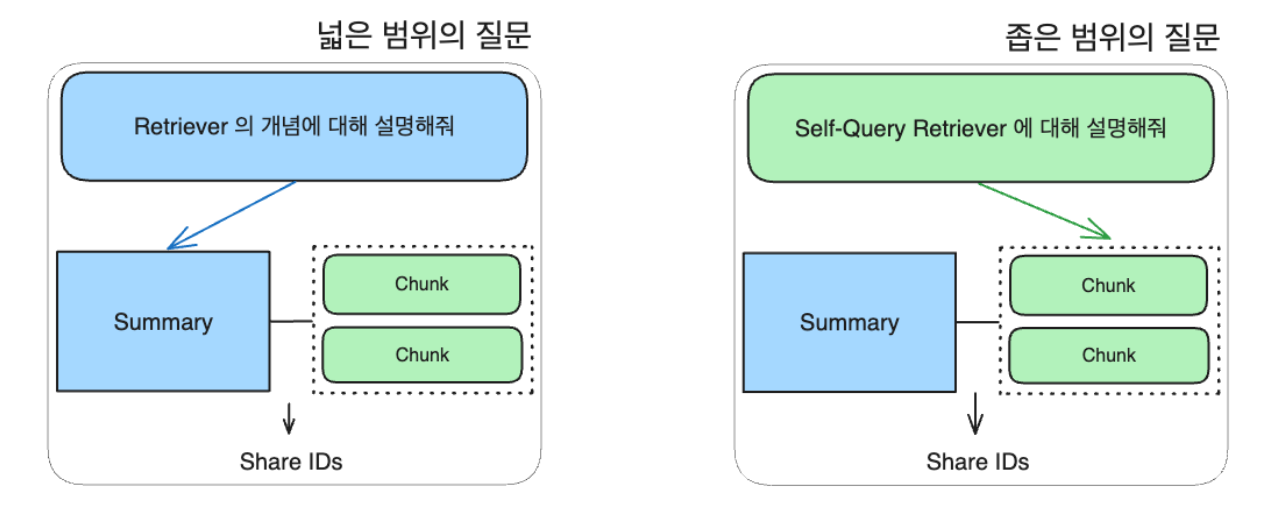
- Self-Query Retriever: Query 문으로 데이터 필터링에 활용
- Summary, Entity 등 추가 정보 생성 후 Indexing
- 추상적인 질문에는 Summary/Entity 활용
- 구체적인 질문에는 작은 Chunk 활용
- Hierarchical Structure
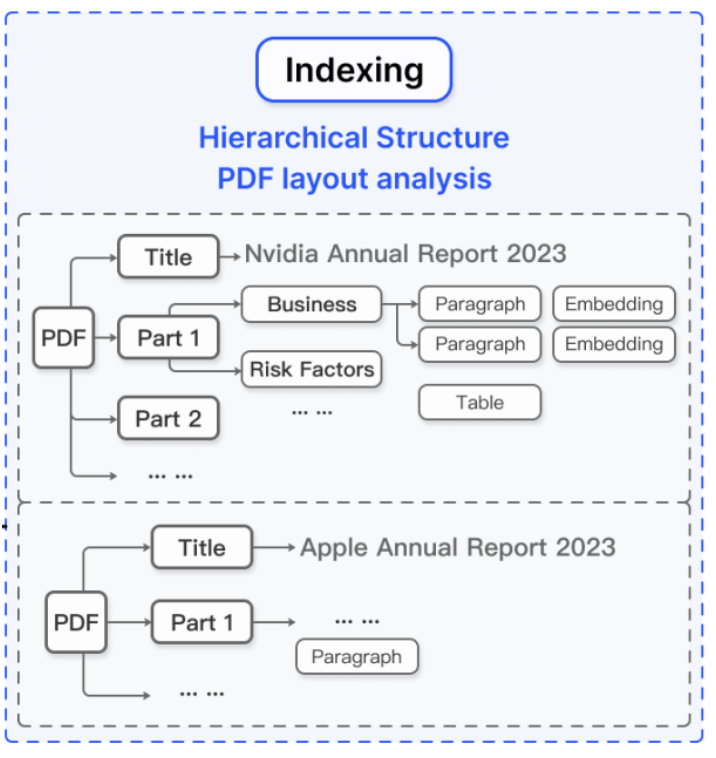
- 계층적 구조로 검색 범위를 좁히고, 대신 검색 Depth를 늘린다.
- Multi-hop 질문의 경우 노드 간의 관계를 활용하여 정확도를 향상한다.
- Multi-hop Question란? 답변을 얻기 위해 여러 단계의 추론이나 정보 조합이 필요한 복잡한 질문 유형을 의미한다.
- Hybrid Indexing
- Relational Database + Vector Database
- RDB
- 구조화된 데이터를 저장
- 사용자의 질문 기반 필터링/대화 내용 저장
- Vector DB
- 문서 내용 기반 유사도 검색에 활용
- RDB
- Relational Database + Vector Database
Chunking Strategy
- Semantic Chunking
- 의미상 유사한 단락을 기준으로 Chunking
- Small-to-Big
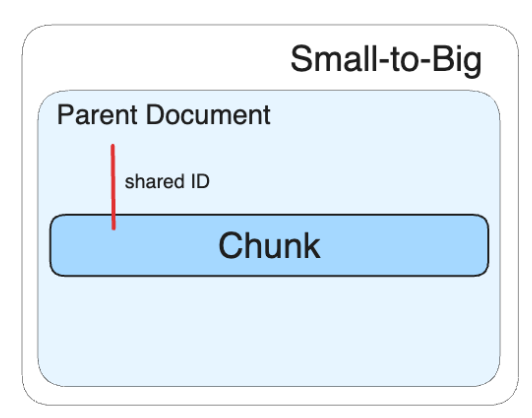
- 자식 ‒ 부모 Document 구조
- 작은 Chunk 단위를 임베딩 한 뒤, Retrieval 단계에서 더 큰 Chunk를 반환
ParentDocument Retriever
- Sentence Window
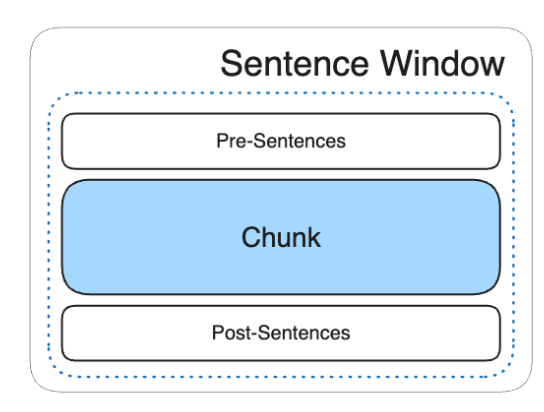
- 단일문장 ‒ 단일문장+주변문장을저장
- 고정된 수(예를 들어 2~3문장)의 주변문장을 저장
- 이후 단일 문장에 Top-N 결과에 포함되면 주변 문장이 포함된 더 큰 Chunk를 반환
Pre-Retrieval
- Query Rewrite
- Query의 의미를 보존하면서 모호성을 제거함.
- 원래 Query의 의미를 유지하면서 더 명확하고 정보가 풍부한 형태로 Query 를 재작성함.
- Query Expansion
- 원래 쿼리에 관련 용어나 동의어를 추가하여 검색 범위를 확장하는 기법이다.
- Query Transformation
- 쿼리의 구조나 형식을 변경
- 예시)
- 일반 질문을 SQL 쿼리문으로 변환
- 일반 질문을 검색에 용이한 구문으로 변환

Retrieval
-
Hybrid Search
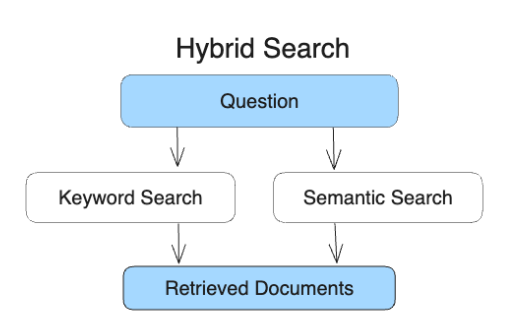
- 키워드검색 + 시맨틱검색
- 키워드 검색: 정확한 단어 매칭을 기반
- 시맨틱 검색: 의미와 문맥을 이해하여 관련 정보 검색
-
Hypothetical Question
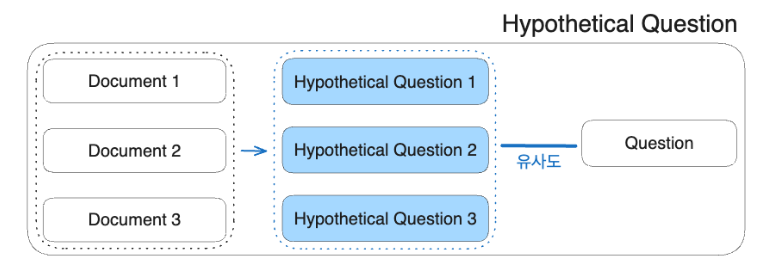
- 문서의 내용을 질문 형태로 변환함으로써, 사용자 쿼리와의 의미적 매칭을 향상
- 각 도큐먼트에 맞는 가상의 질문을 생성
- 생성된 가상의 질문을 임베딩
- 사용자쿼리와가상질문임베딩간의유사도계산
-
HyDE(Hypothetical Document Embeddings)
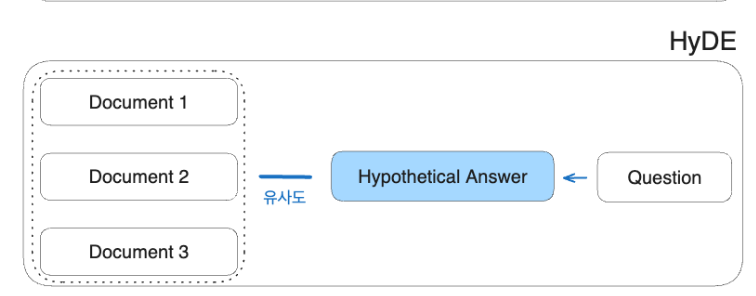
- 생성된 답변이 직접 쿼리보다 임베딩 공간에 더 가깝다는 가정에 기초
- 사용자 쿼리에 대한 가상의 답변을 생성
- 생성된 답변을 임베딩
- 답변과 답변 간의 임베딩 유사성을 강조
Post-Retrieval
-
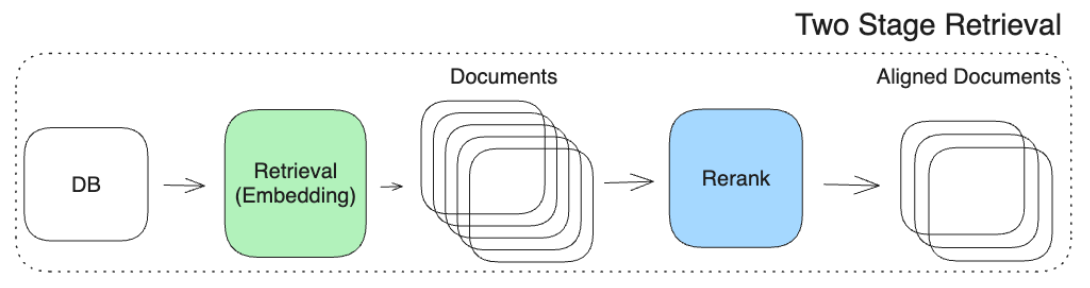
Reranker
- 각 Query ‒ Document 쌍의 관련성을 평가
- Retriever가 대규모 문서 집합에서 빠르게 후보를 추출하는 데 초점을 맞추는 반면, Reranker는 이미 추출된 소수의 후보에 대해 더 정교한 분석을 수행
- Retriever와 Reranker 를 결합한 Two Stage Retrieval pipeline 주를 이룸.
-
Context Reorder
- LLM은 입력 텍스트의 초반부와 후반부에 있는 정보를 더 잘 활용한다.
- 덜 관련된 문서는 목록의 중간에 배치하고, 관련성이 높은 문서는 시작과 끝에 배치한다.
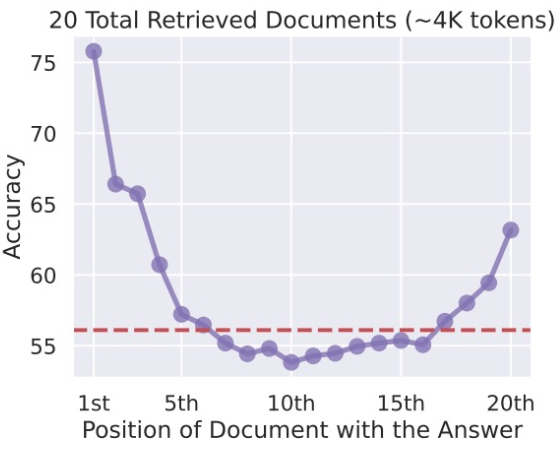
- 출처: Lost in the Middle(https://arxiv.org/pdf/2307.03172)
-
Compressor
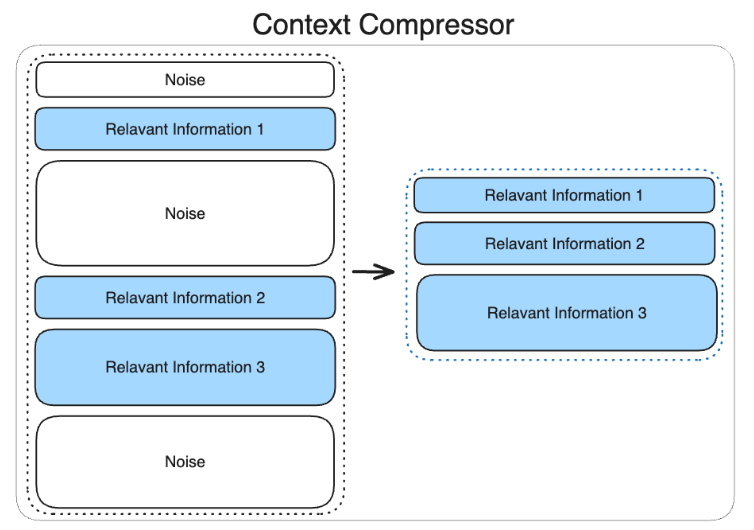
- 관련성이 낮은 정보를 제거하여 LLM에 입력되는 컨텍스트의 품질을 향상
- Context Precision: 검색된 정보 중에서 실제로 관련 있는 정보의 비율
- 할루시네이션 발생 가능성을 줄이는 데 도움
- 토큰 비용 효율화(답변의 품질을 유지하면서 입력 크기를 줄임)
- 처리속도 향상
-
주요 방법론
- LLMChainExtractor: 쿼리와 관련된 컨텍스트만 추출
- Lexical-based Compression
- LLMLingua
- 문맥(Context) 에서 중요한 토큰을 선별한 뒤, 쿼리 기반 토큰 Classifier가 중요 토큰 선별
- Embedding-based Compression
- 임베딩을 사용하여 관련성 높은 정보 필터
- COCOM(COntext COmpression Model)
- Compressor Model 을 파인튜닝하여 압축에 활용
Advanced RAG의 한계
고급 RAG의 실용성이 개선되었음에도 불구하다.
기능과 실제 애플리케이션 요구 사항 사이에는 여전히 격차가 존재한다.
프로덕션(Production)의 어려움
- RAG 기술이 발전함에 따라 사용자의 기대치가 높아짐
- 요구사항이 계속 진화, 애플리케이션이 더욱 복잡
- 다양한 형태의 데이터의 통합
- 파이프라인의 제어 및 유지보수의 어려움
Linear Structured RAG의 한계
Naive RAG, Advanced RAG 모두 단방향 구조의 RAG이다
Document Loader(데이터로드) -> Answer(답변)
- 모든 단계를 한번에 다 잘해야 한다.
- 이전 단계로 되돌아가기 어렵다.
- 이전 과정의 결과물을 수정하기 어렵다.
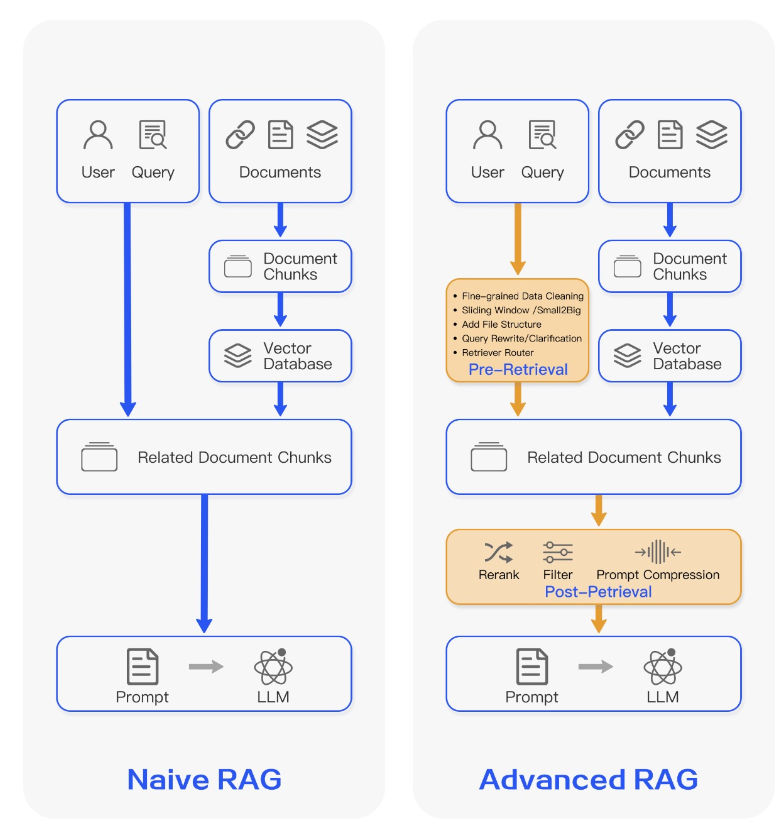
Modular RAG
LEGO와 같은 재구성 용이하고 보다 유연한 흐름을 만들 수 있는 프레임워크
- 독립적(Independant): 기능 위주로 세분화되어 있다.
- 유연하고 확장성(flexable&scalable): 모듈의 추가 및 변경이 쉽다.
- 동적(dynamic): 그래프 형식의 흐름 구성, 상황에 따른 분기 처리가 가능하다.
모듈
모듈, 하위 모듈 및 운영자로 구성된 아키텍처 설계를 통해 통합되고 구조화된 방식으로 RAG 시스템을 정의한다.
-
각 단계(Step)를 모듈(Module)별로 정의한다.,
- 각 모듈은 하위 모듈(Sub Module)로 구성된다.
-
하위모듈은 플러그인 형식의 독립된 구조를 가지고 있다.
- 독립 구조: 각 모듈은 조립형으로 설계(LEGO 블록)
- 병렬 구조: 여러 하위 모듈을 동시 실행 후 병합 가능
- 분기 구조: 상황에 따른 분기 처리가 가능
독립적인 모듈 구성
동일한 형태의 입력과 출력을 반환하는 Interface을 작성한다.
- LEGO 방식의 조립이 가능한 Module로 설계한다.
- 내부구현은 모듈별 목적에 따라 다르게 구현한다.
def custom_retriever(data: RagData) -> RagData:
# 커스텀 retrieve 로직 구현
...
return data
def request_private_api(data: RagData) -> RagData:
# API 호출 로직 구현
...
return data
조립형 모듈
마치 LEGO 블록처럼 세부 모듈(Sub-Module) 을 연결하여 구성할 수 있다.
- 모듈의 추가/변경이 용이하다
독립적인 모듈의 장점을 활용할 수 있다.
- 각 Sub-Module의 교체가 쉽다
- 단계의 전/후에 Sub-Module을 추가하는 것이 쉽다.
그래프 형식의 동적 흐름 구성
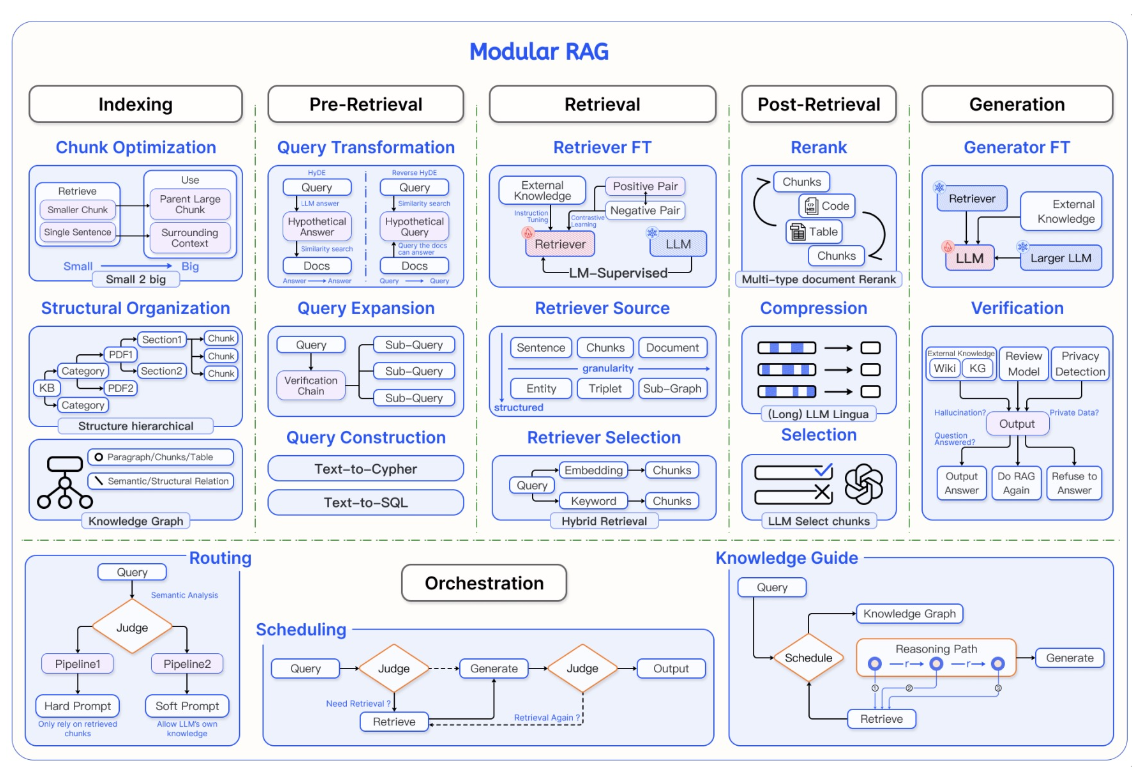
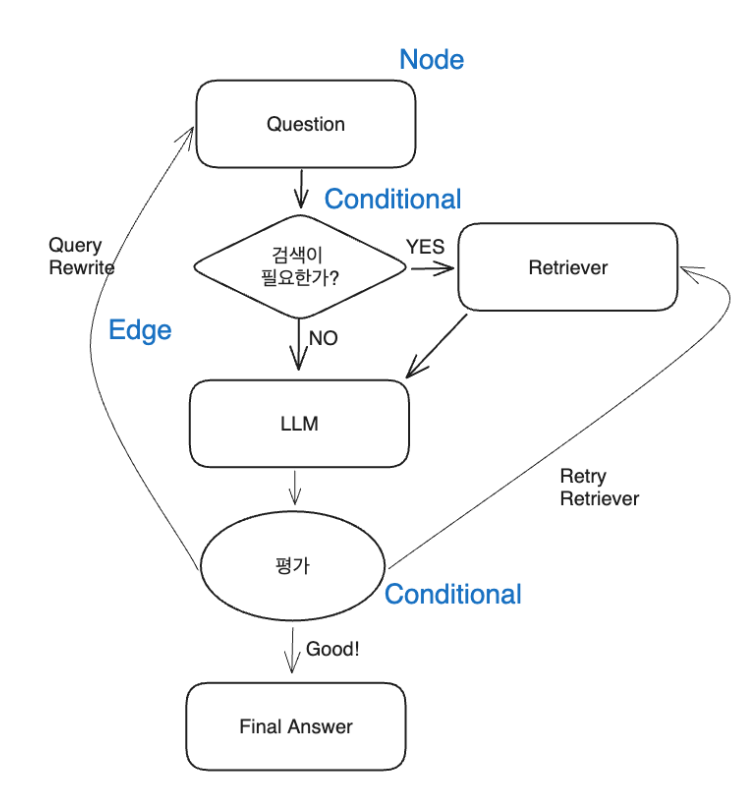
- 평가자 -> “문서검색”에 대한 평가(Score)
- 검색된 문서가 Query 답변을 위한 정보가 충분한지 판단
- Success: 답변 생성
- Fail
- 검색된 문서의 정보가 불충분한 경우 -> 문서 검색을 위한 Query Rewrite
- 질문이 모호한 경우 -> 보다 명확한 질문 또는 Query Decomposition 을 통한 세부 질문으로 구성 후 검색
- 검색된 문서가 Query 답변을 위한 정보가 충분한지 판단
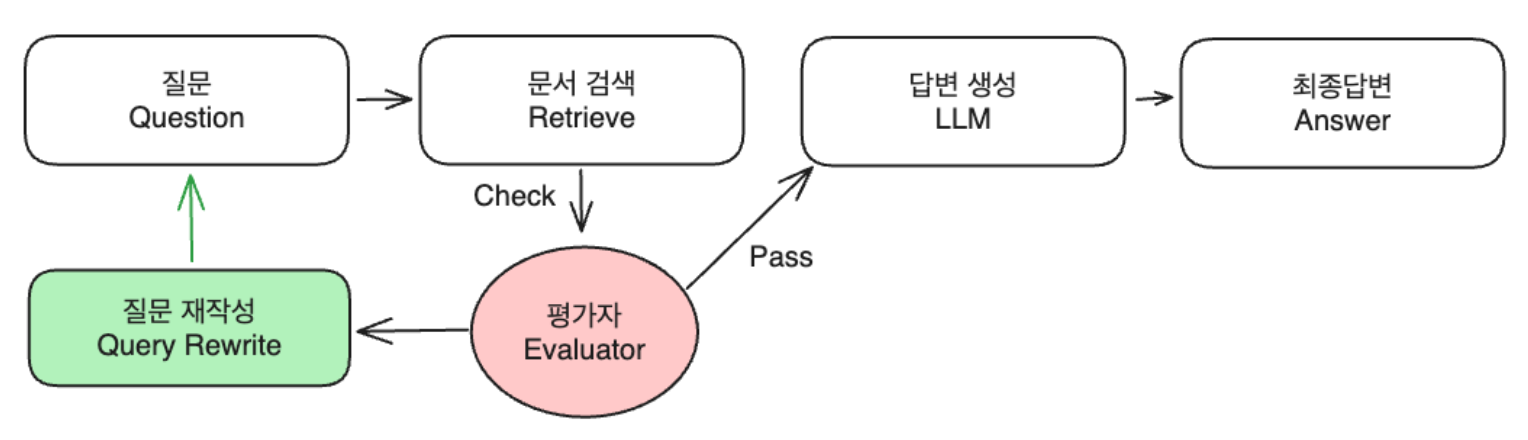
- Query -> 문서검색 -> 답변생성 -> 평가자 -> “답변”에 대한 평가(Score)
- Query에 대한 답변이 충분한지 평가
- Success: 답변 생성
- Fail
- 질문이 모호한 경우 -> Query Rewrite
- 정보가 불충분한 경우 -> 추가 검색 모듈(Web Search) 을 활용하여 통하여 문맥(context) 보강: Web Search
- Query에 대한 답변이 충분한지 평가
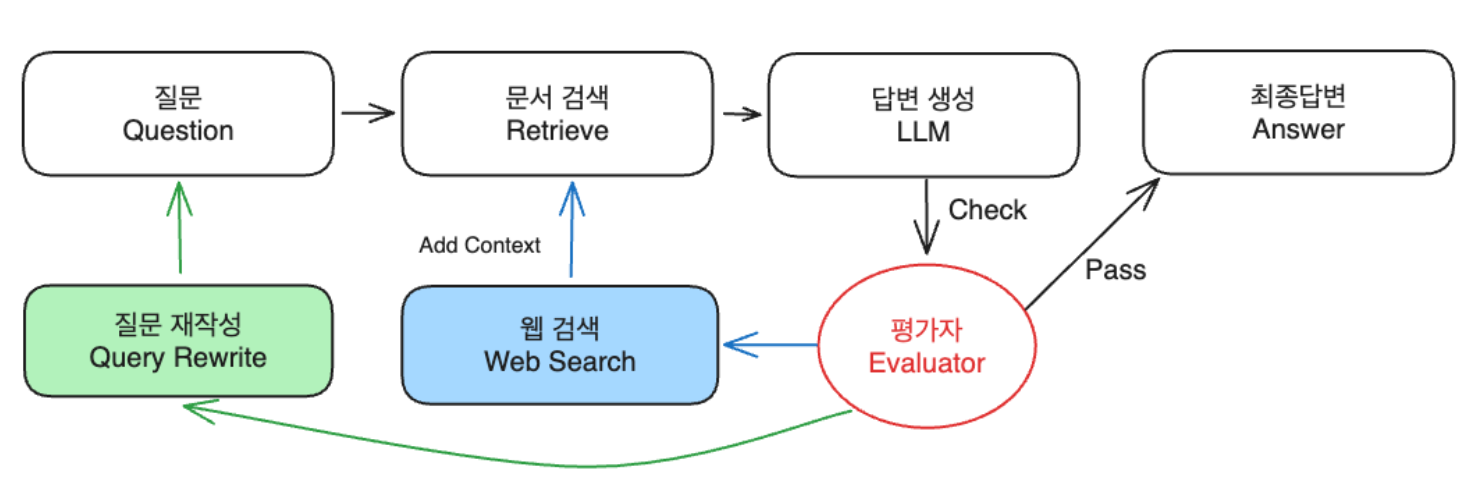
- 질문에 문서 검색이 필요한지 평가자1이 판단하여 Routing
- YES -> 문서 검색 -> 답변 생성
- NO -> 문서 검색하지 않고 즉각 답변 생성
- 토큰 비용의 절약
- 예시) “대한민국의 수도는 어디입니까?” -> 즉각 답변
- 평가자2는 RAG 답변에 대한 평가
LangGraph
https://github.com/langchain-ai/langgraph
워크플로우(Workflow)를 만드는 데 사용한다.
상태 저장, 멀티 액터(Multi-Actor) 애플리케이션을 구축에 용이한 라이브러리이다.
핵심 기능
- Cycle & Branching: 루프 및 조건문을 구현
- Persistance: 그래프의 각 단계 후에 자동으로 상태를 저장하고, 노드‒노드간 상태값을 전달한다.
- Low Level Control: LangGraph는 LangChain 없이도 사용 가능하다.
주요 구성 요소
- Node(노드)
- Sub-Module: RAG 안의 세부 기능을 정의
- Edge(엣지)
- 노드‒노드간 연결을 정의
- 1:N, N:1 연결도 지원 (병렬 처리)
- Conditional Edge(조건부엣지)
- 조건에 따라 분기 처리
- State(상태)
- 현재의 상태값을 저장 및 전달하는 데 활용
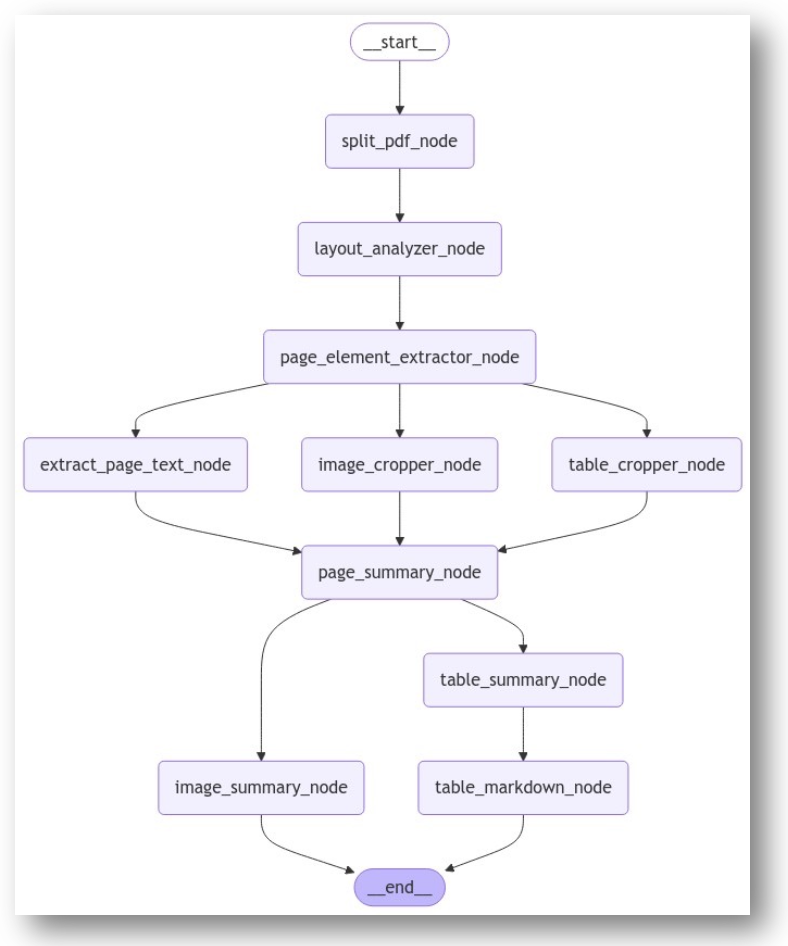
LangGraph 구현 예시
- Node를 정의(split_pdf_node, ...)
- Node ‒ Node간 Edge로 연결하여 그래프 구조화
- 병렬 처리 후 합산 가능
- 그래프를 출력하여 로직을 쉽게 확인 가능
- LangGraph Studio
- Human in the Loop (사람의 개입)
- 동적 메시지
- 각 노드의 결과물을 실시간 출력
Modular RAG Patterns
Linear Pattern
- 선형 흐름 패턴은 가장 단순하고 가장 일반적으로 사용되는 패턴
- RAG 흐름 패턴은 주로 검색 전처리 - 검색 - 검색 - 후처리 및 생성 모듈로 이루어진 구성

- Pre-Retrieve
- QueryTransform
- Rewrite Query, HyDE
- Post-Retrieve
- Reranker,Reorder
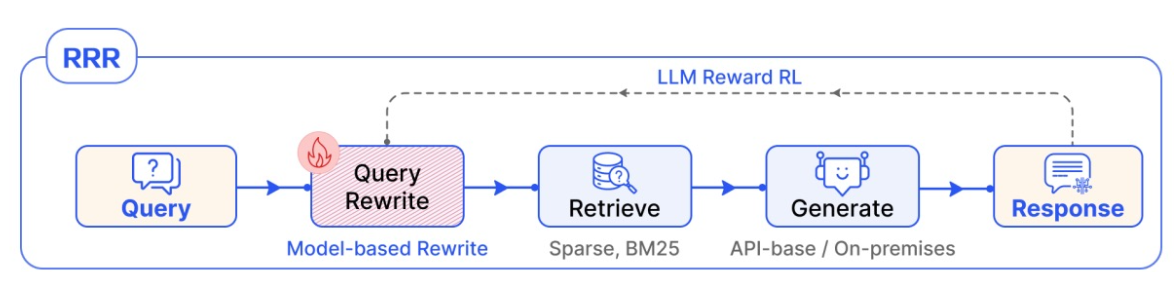
- Rewrite ‒ Retrieve ‒ Read(RRR)
- RRR
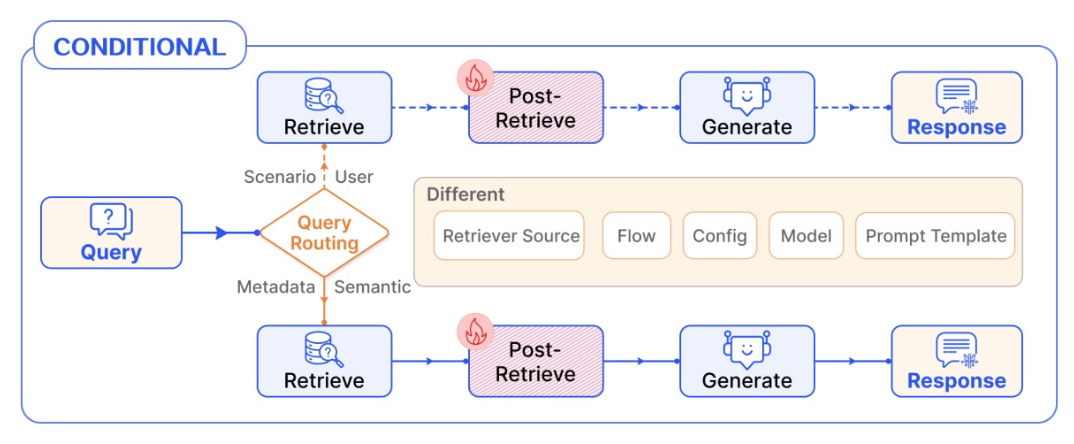
Conditional Pattern - Routing
- Conditional Routing
- Query 입력에 따라 RAG 파이프라인을 선택
- 라우팅 모듈이 존재
- 예시) 입력된 Query 에 따른 검색기 선택
Branching Pattern
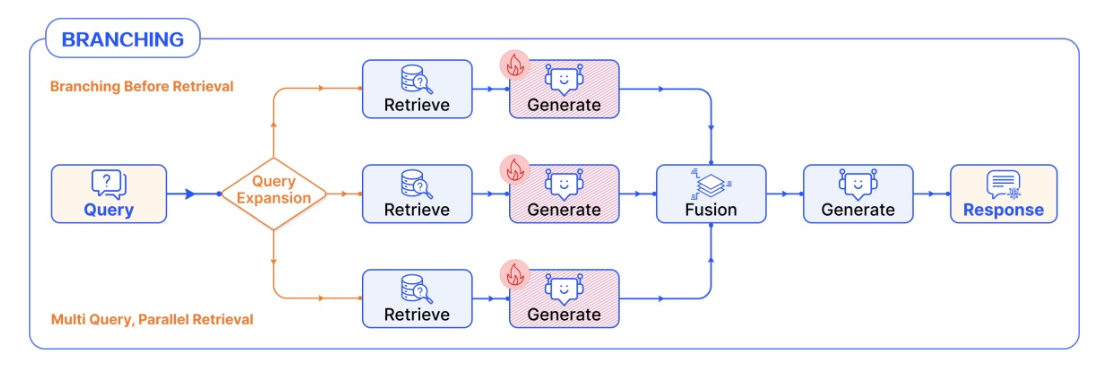
- Pre-Retrieve
- 검색소스/검색프로세스/프롬프트/모델 등이 달라짐
- 각 브랜치는검색&생성을 개별적으로 수행한 다음 결과를 앙상블한다.
- 예시) Query3개 생성 ‒ 검색 ‒ 생성 ‒ 결과
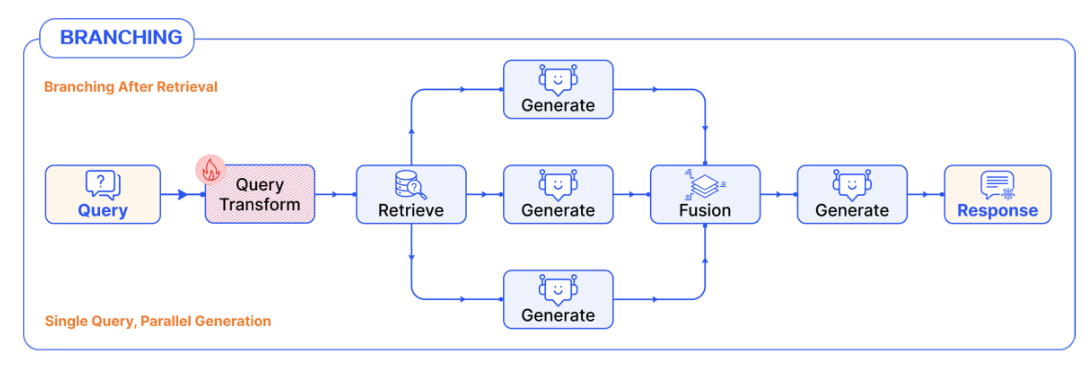
- Generation
- 모델이 동일한 문맥(Context)으로 각각의 답변을 도출한 다음 결과를 앙상블한다.
- 예시) GPT-4o, Claude 3.5 Sonnet, Llama3.1
- 모델이 동일한 문맥(Context)으로 각각의 답변을 도출한 다음 결과를 앙상블한다.
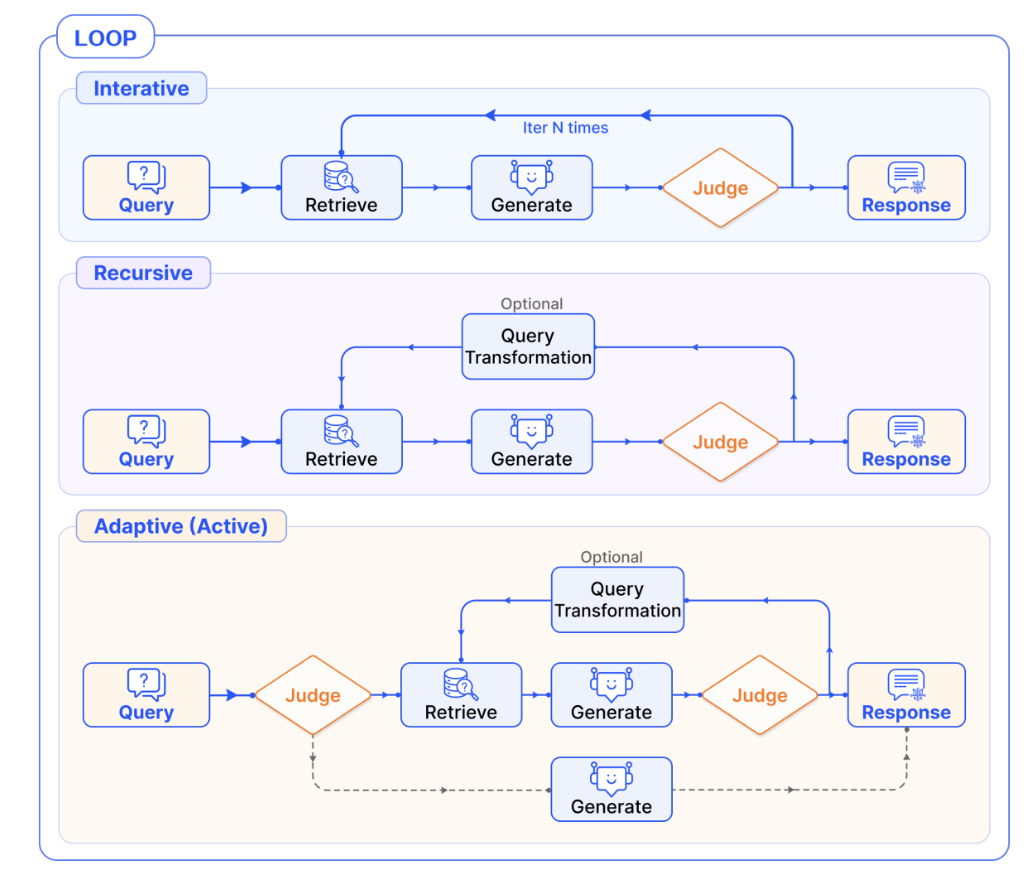
Loop Pattern
Iterative N Pattern
반복적인 검색 - 생성 과정을 통해 복잡한 질문에 대한 답변의 품질을 향상한다.
동작 방식
- 검색(Retrieval)과 생성(Generation)단계를 여러번 반복
- 미리 정해진 최대 반복횟수(N)까지 프로세스를 반복
- 각 반복마다 이전 출력을 활용하여 더 관련성 높은 정보를 검색하고 답변을 개선
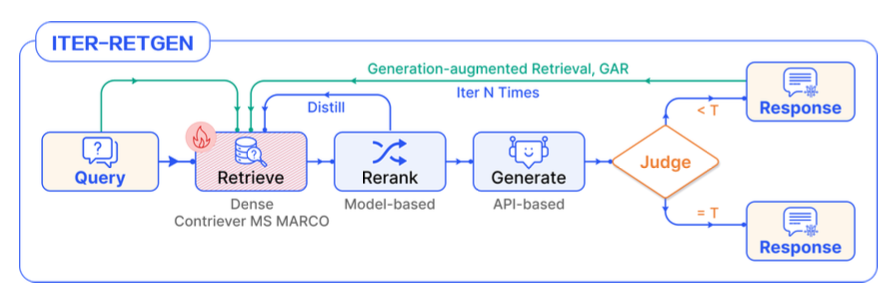
ITER-RETGEN
https://arxiv.org/pdf/2305.15294
Generation Augmented Retrieval(GAR)
- 검색된 문서 기반 LLM 답변 생성
- 생성된 답변을 Query와 결합하여 검색 수행
- 새롭게 검색된 문서 기반으로 LLM 답변 생성
- N회 반복 후 최종 답변 도출
Tree of Clarification
- https://arxiv.org/pdf/2310.14696
- 모호한 질문을 구체화 해나가는 과정
- 각 노드에서 LLM 은 해당 질문에 대한 답변 생성(w/ Ambiguous Question)
- Question Clarfication 을 위한 하위 노드 추가(Disambiguous Question)
- 관련없는 노드 pruning/관련성 있는 정보만 남김
- 생성한 정보를 종합하여 Long Form 답변 생성

Adaptive Retrieval Pattern
Retrieval 전 단계에서 Retrieval 과정이 필요한지를 판단
동작 방식
검색(Retrieval)이 필요한 질문인지 판단
- 검색이 필요하지 않은 경우 -> 즉각답변생성
- 검색이 필요한 경우 -> ITER-N 혹은 Recursive Retrieval Pattern 실행
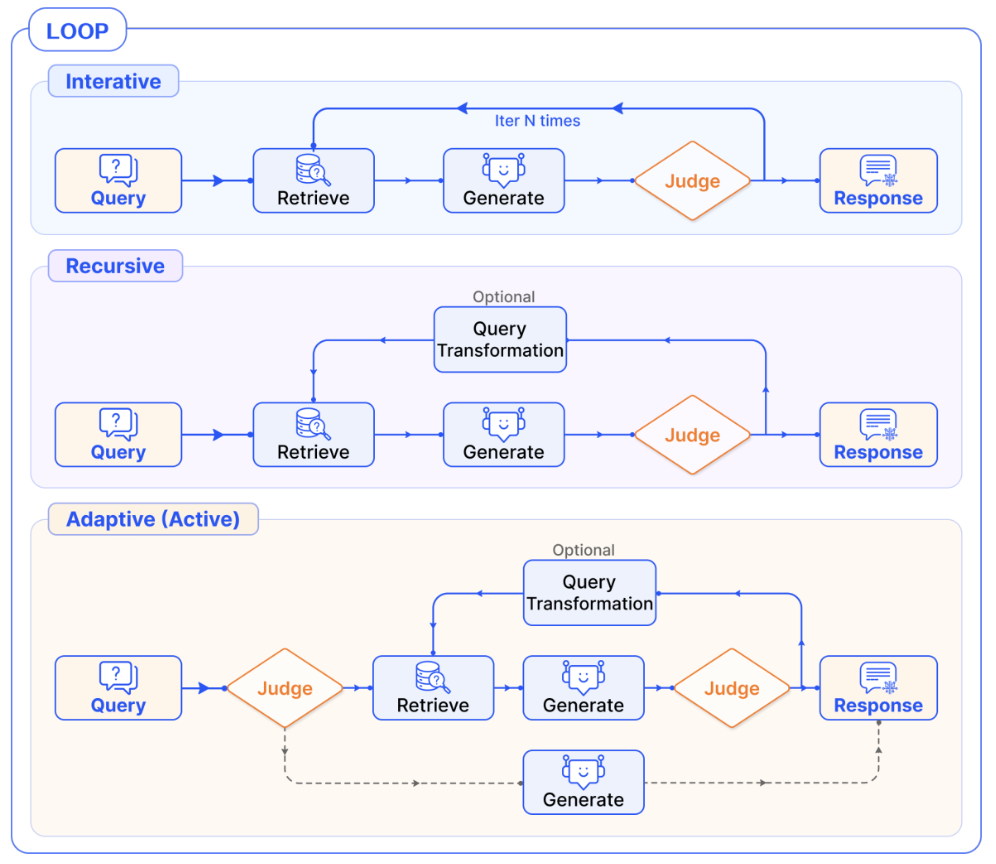
Adaptive Pattern
Forward-Looking Active Retrieval (FLARE)
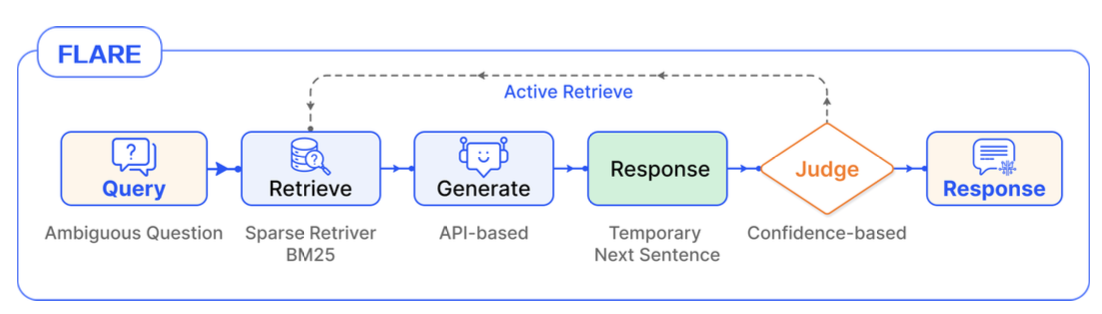
- 답변을 생성함에 있어 Retrieval 이 필요한지 판단
- 답변에 대한 신뢰도(Confidence)를 측정하여 동적으로 Query 를 구성
동작방식
- 쿼리 입력
- 모델이 토큰을 생성하며 다음 문장을 반복적으로 예측
- 모델이 생성한 답변이 confidence 가 낮다면, 생성된 문장을 Query 로 문서 재검색
- 재검색한 문서+생성한 문장을 입력으로 새로운 답변 생성
- 응답이 완성될 때까지 2~4Step을 반복 수행
응용한 Self-Reflective RAG
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection을 응용한 버전이다.
Self-RAG 논문에서는 reflection 토큰으로 retrieval 하는 시기를 판단한 다음 -> LLM as a Judge 로 대체한다.
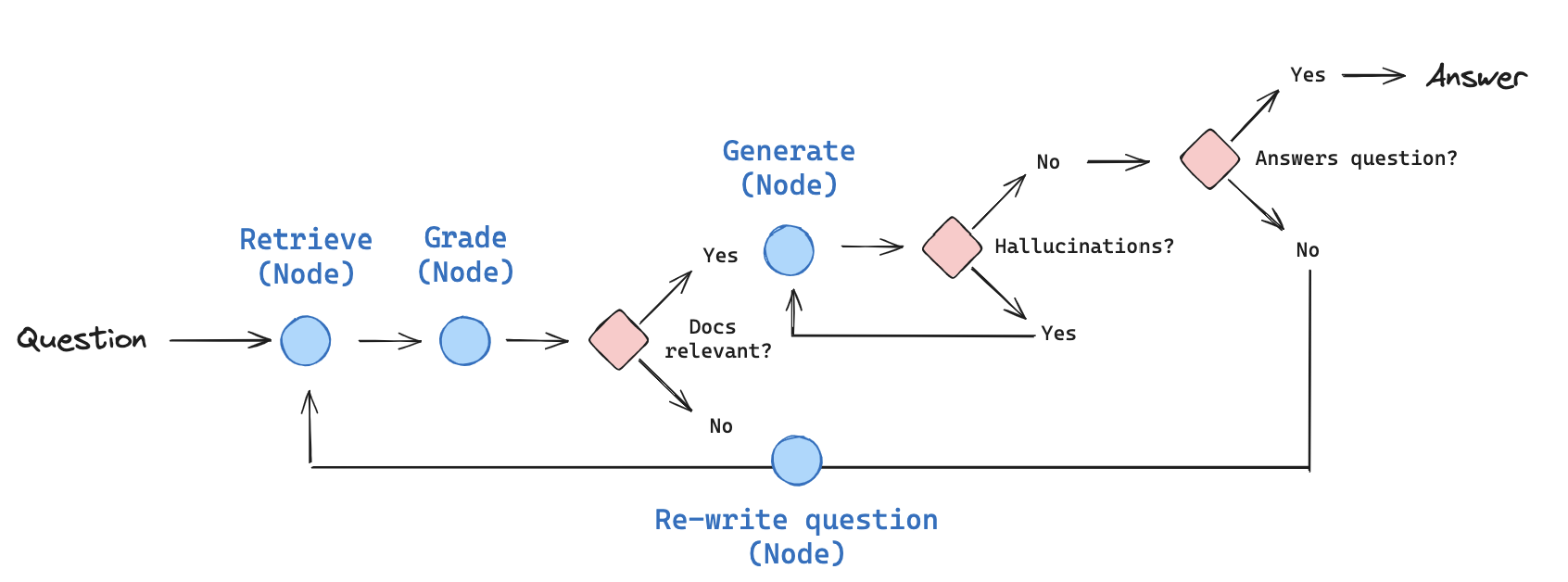
동작 방식
- 문서 Retrieval 후 관련성 평가
- 관련성이 있다면 답변생성, 관련성이 없다면 QueryRewrite 후 Step1 진행
- 답변에 대한 Hallucination 평가
- Hallucination 판별 시 답변 재생성, 없다면 Relevance 체크
- RelevanceCheck 통과 시 최종 답변, 실패시 QueryRewrite 후 step1 진행
그 밖의 수많은 RAG 패턴들
Modular RAG 적용 사례: 복잡한 구조의 문서 처리
Graph Parser Modular - 주요 기능
일반 텍스트 처리
- 불필요한 특수문자, 관련성없는 정보제거
- 모호한 용어, 중복된 텍스트 제거
- 도메인에 특화된 주석 추가
표, 이미지 처리
- 표 / 이미지를 Markdown 형식으로 변환
- 표에 대한 요약문 생성
- 이미지를 검색에 활용하기 위한 임베딩용 텍스트 변환
- 이미지에 대한 Entity 추출
- 이미지에 대한 요약문 생성
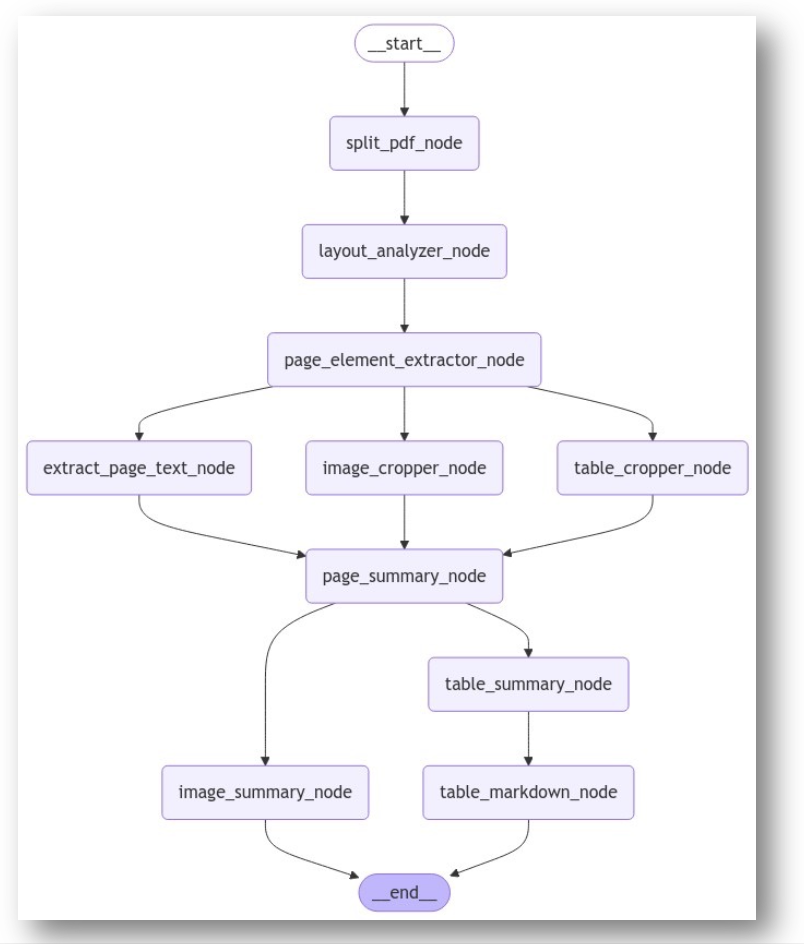
Graph Parser Modular - Base 노드 & 상속
BaseNode상속abstractmethod구현
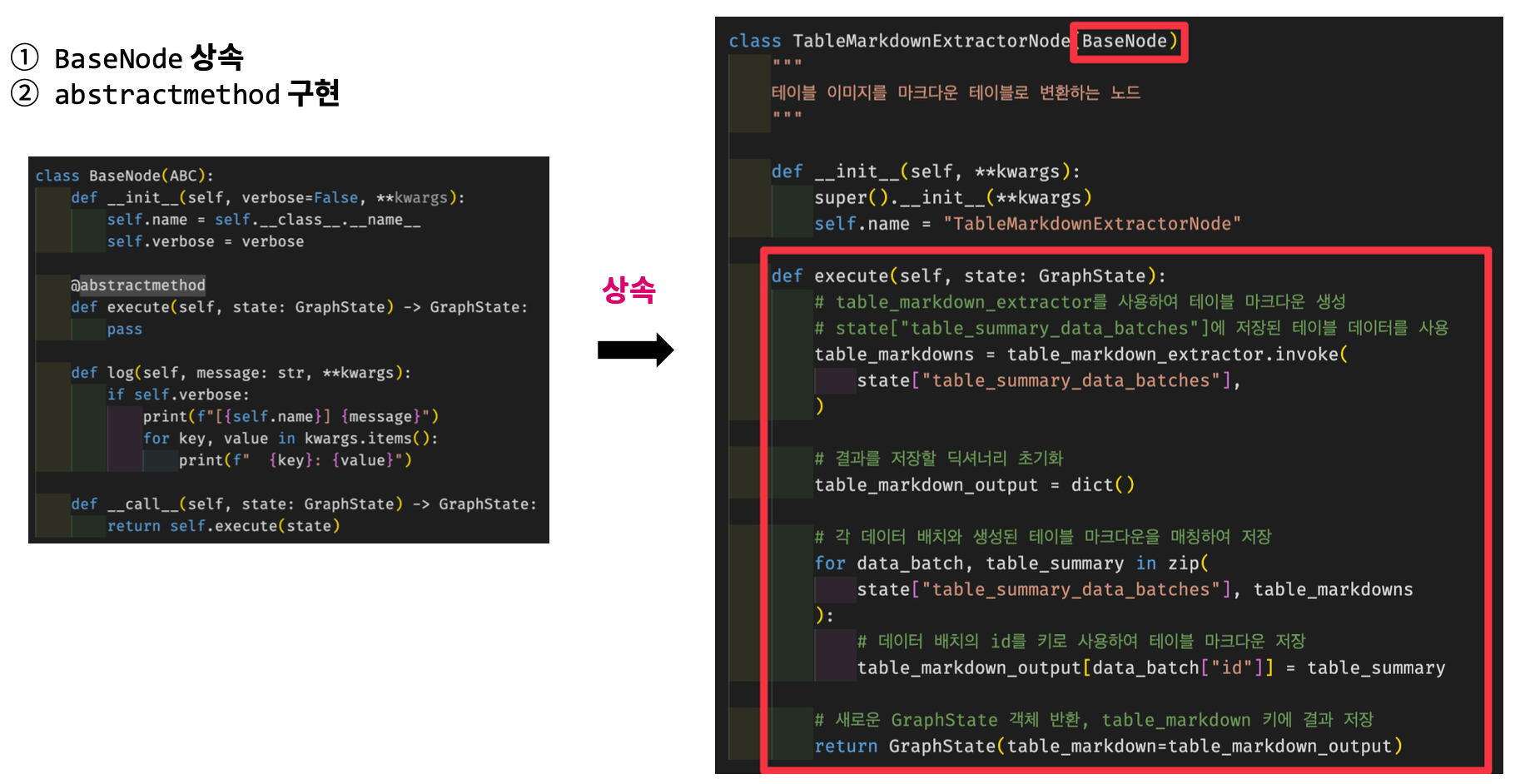
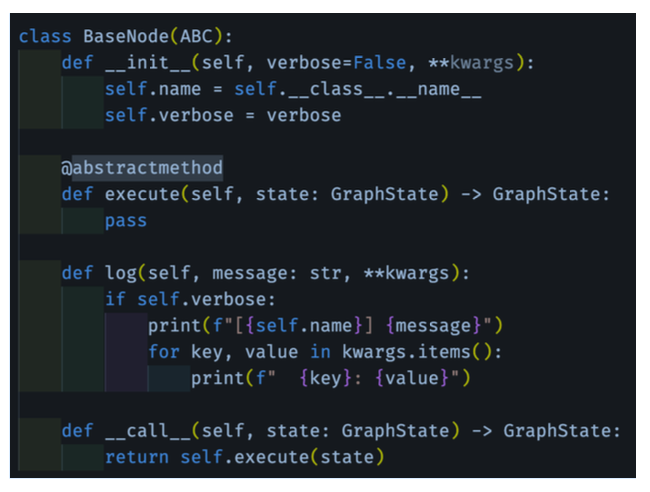
⬇️ 상속
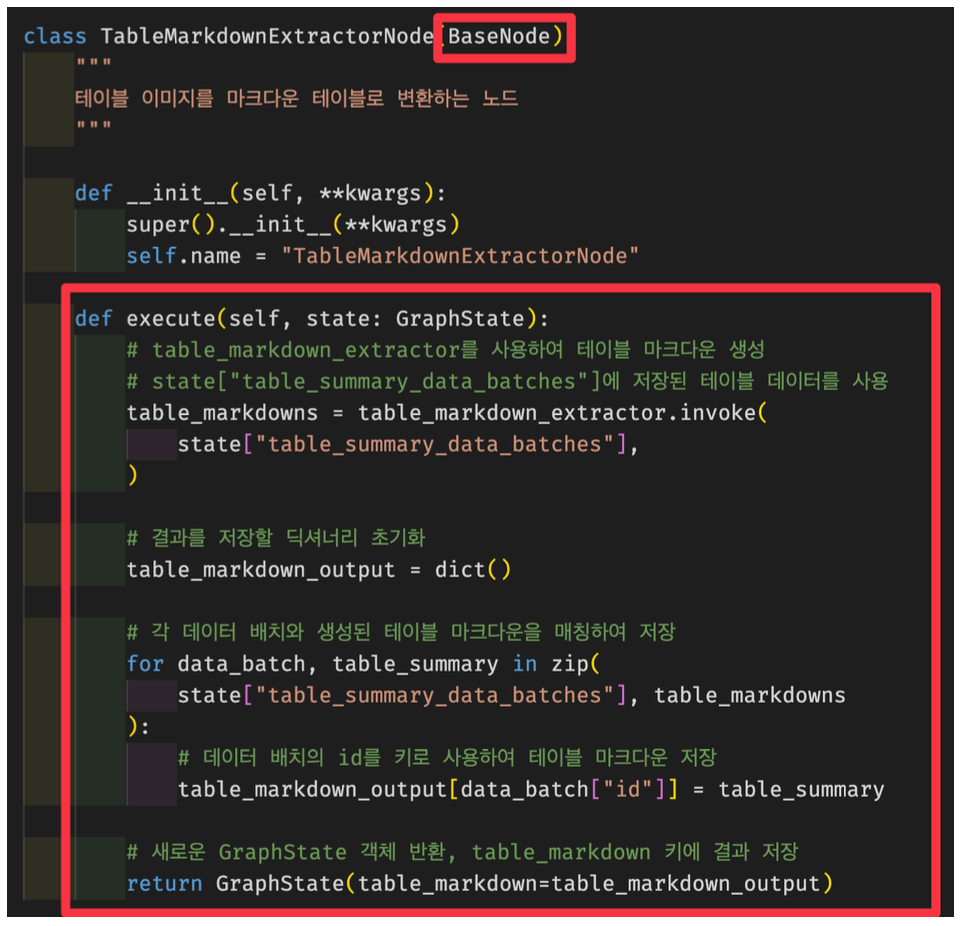
Graph Parser Modular - 기능별로 분리(재사용)
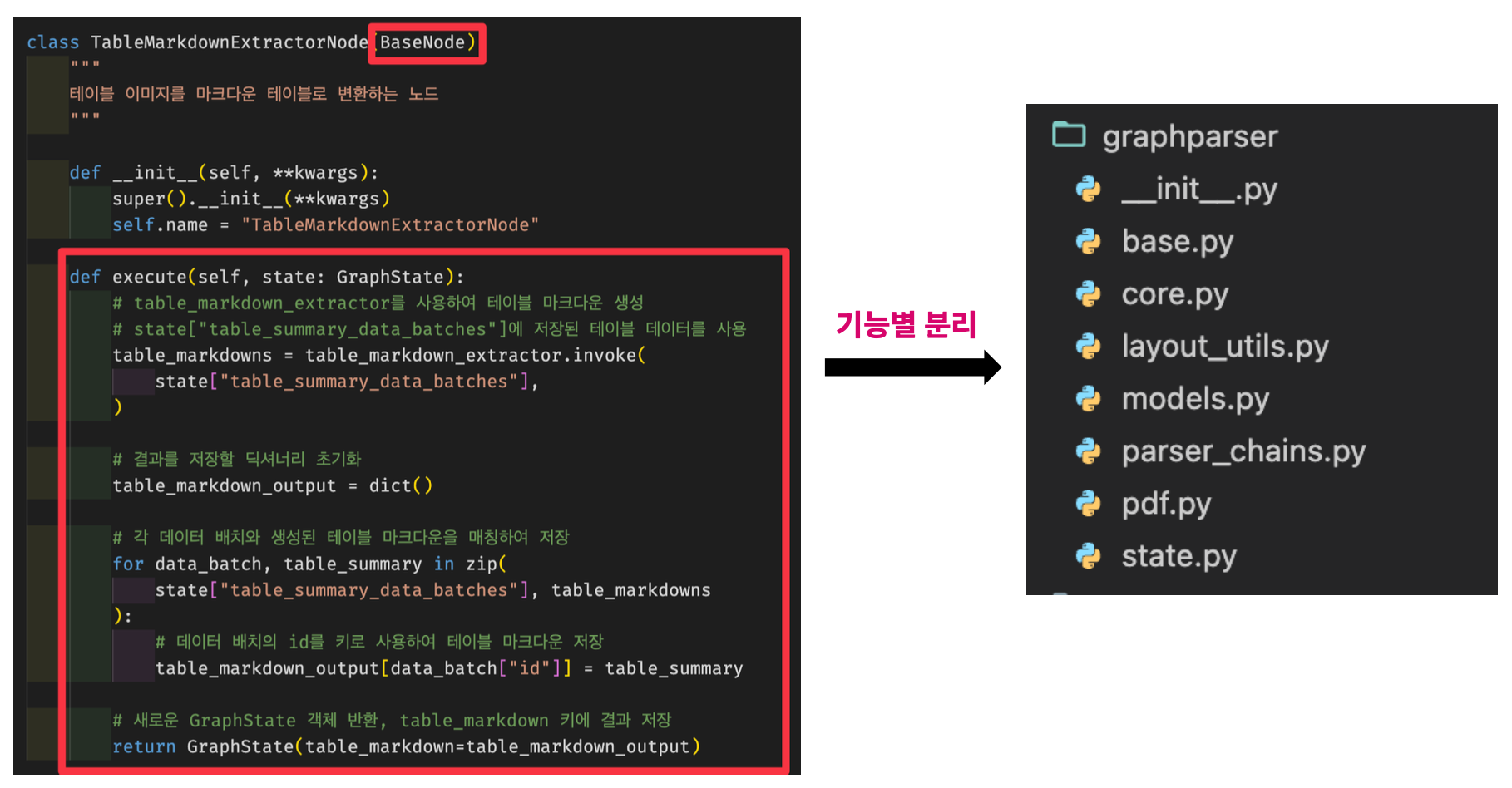
Graph Parser Modular - 그래프 정의

Graph Parser Modular - 흐름 및 다양한 테스트

텍스트 추출

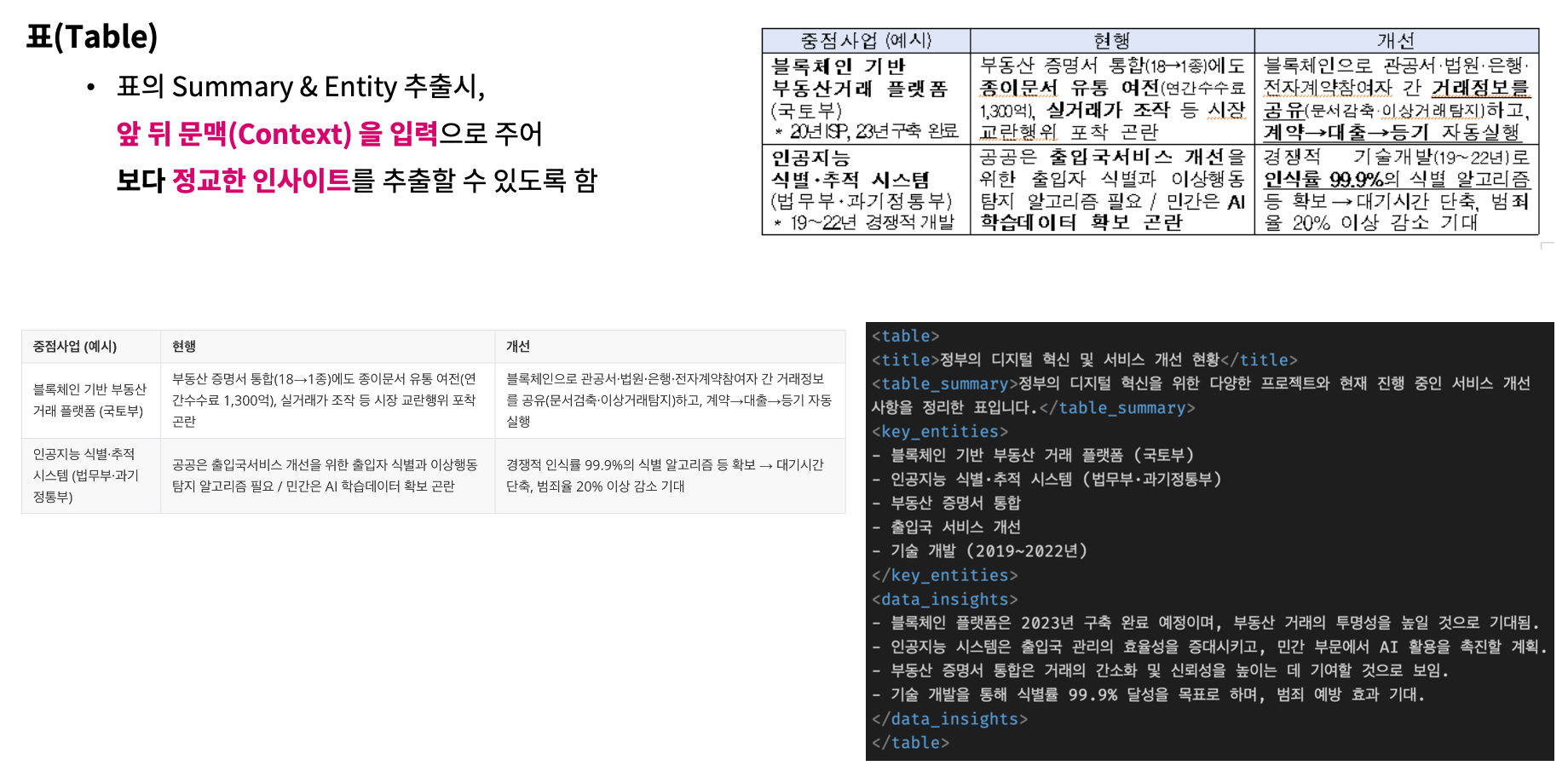
표(Table) 추출
표의 Summary & Entity 추출시, 앞 뒤 문맥(Context) 을 입력으로 주어 보다 정교한 인사이트를 추출할 수 있도록 함
이미지 추출

요약
LLM의 발전은 소프트웨어 개발에서 완전히 새로운 문제에 접근할 수 있다는 점에서 놀랍습니다.
하지만, 이를 충분히 활용하려면 문제를 해결하기 위해
쪼갤 수 있는 가장 작은 단위로 나누고
작은 단위의 모듈이 작은 범위의 작업에 집중할 수 있도록 해야 합니다.
모듈식 접근 방식은 단순한 기능 외에도
전체 시스템을 접근하기 어려운 블랙박스로 만들지 않고
개별 구성 요소를 디버깅하고 반복할 수 있는 기능을 제공합니다.
RAG 설계에는 다양한 방법론들이 존재하고, 때로는 창의적 접근이 필요한 분야입니다.
LLM의 성능 개선과 토큰 비용 절감은
LLM을 답변 생성의 기능이 아닌 평가자(Judge), 라우터(Router) 와 같이 RAG의 하나의 기능으로 활용하게 되면서 더 창의적인 방법론들이 제시될 전망입니다.
정해진 최적의 해는 없기 때문에 지속적인 실험과 시행착오가 경쟁력 입니다.
그리고, RAG의 각 세부 기능을 Module 화 해야 수 많은 실험을 체계적으로 시행할 수 있습니다.